2025年8月26日に「生成AI活用データ分析術〜BigQuery・Looker Studioと生成AIで実現する、示唆だし自動化の実践法〜」というテーマでウェビナーを開催しました。ご参加いただいた皆様、誠にありがとうございました!
本ウェビナーでは、BigQuery・Looker Studioに蓄えられたデータから生成AIを活用して示唆を抽出するための実践的な知見について解説しました。この記事では、本ウェビナーの内容をまとめてご紹介します。
1. 生成AIとデータ活用の全体像
①生成AIの登場による変化
生成AIの登場により、自然言語操作で誰もがデータ活用できる時代へと変化しています。データ分野においては、生成AIの活用がより重要になっています。
データ分野での生成AI活用の具体例として、以下の5つが挙げられます。
- 自然言語でのデータクエリと分析の実現
SQLやプログラミングの専門知識がなくとも、普通の言葉でデータ分析が可能です。 - データ分析の民主化と裾野拡大
技術的障壁が低下し、ビジネス部門でも高度な分析が実行できます。 - データ可視化とインサイト発見の自動化
AIによる最適なグラフやダッシュボードの提案により意思決定スピードが加速しています。 - 分析レポート作成の効率化と時間短縮
AIによる自動要約・レポート生成によりデータからインサイトへ迅速に変換できます。 - パターン検出と異常検知の高度化
従来は発見困難だった複雑なデータパターンや異常のAIによる自動検出が可能です。
②生成AIに任せられないこと
一方で、データ活用における全てをAIに任せることは出来ません。特に、意思決定・定義づけはAIではなく人間の役割です。
以下はその具体例です。
- ビジネス目標と価値観の設定
AIはツールであり、「なぜそれを行うのか」という目的や価値判断はできません。 - データの文脈理解と業務知識の適用
業界特有の暗黙知や経験則に基づく解釈は、人間の専門性が不可欠です。 - 複数視点からの倫理的判断
データ分析から得られた洞察の倫理的妥当性や社会的影響の評価は人間の役割です。 - 組織的合意形成と責任の所在明確化
最終的な意思決定と結果に対する責任は常に人間が担います。 - 継続的な学習と改善の指示
分析結果から何を学び、どう改善するかというフィードバックループの設計・整理はAIにはできません。
③従来のデータ活用プロセス
上記を踏まえ、生成AI登場前後でのデータ活用プロセスを比較します。従来の分析は人手依存で非効率でしたが、AIの登場によりデータ活用のプロセスは効率化されました。
以下に、従来のデータ活用プロセスにおける課題点をまとめました。
- データ抽出の手作業と時間のロス
データベースからの抽出作業に専門知識が必要で、リクエストから納品まで数日を要する事例が多数ありました。 - 属人化によるデータ加工の品質ばらつき
担当者のスキルによって前処理の方法が異なり、同じデータでも異なる結果が生まれていました。 - レポート作成の反復作業による非効率
定期レポートの更新作業に毎回同じ工数がかかり、分析時間が圧迫されていました。 - 可視化・資料作成の手動プロセス
Excelやパワーポイントでの手作業によるグラフ作成は時間がかかり、ミスが発生しやすい傾向がありました。 - データ更新の維持コストと鮮度の低下
自動化されていないため更新頻度が下がり、古いデータに基づく意思決定が行われるリスクがありました。
④生成AIによる補助ポイント
これらの課題に対して、生成AIがSQL生成やチャート提案を補助することで、作業効率が飛躍的に向上しています。
以下は、生成AIによる分析補助の具体例です。
- SQLやデータ分析コードの自動生成
自然言語での指示だけで複雑なクエリを生成し、データエンジニアの作業時間を削減します。 - データクレンジングと前処理の効率化
異常値検出や欠損値処理など、データ準備作業を自動化し、分析準備時間を短縮します。 - 最適な可視化方法の自動提案
データの特性に合わせた効果的なチャート・グラフ形式を提案し、伝わりやすいダッシュボード作成をサポートします。 - レポートの自動生成と要約
データ分析結果から重要ポイントを抽出し、経営層向けの簡潔なレポートを自動作成します。 - 異常検知と予測モデルの構築支援
従来統計や機械学習の高度な知識が必要であったモデル構築をサポートします。
つまり、データ活用プロセスを効率化するためには、AIの補助範囲と限界を理解することが生成AI活用の第一歩です。
2. ステップ別 生成AIの関わり方
①ステップ別 AI活用
データ活用プロセスは複数のステップから構成されており、各ステップで生成AIの得意分野と人間の判断が必要な領域があります。そのため、効果的な活用のためには、AIと人間の役割分担を明確化することが重要です。
以下では、データ活用を4つのステップに分け、各ステップにおけるAIと人間の役割分担を説明します。
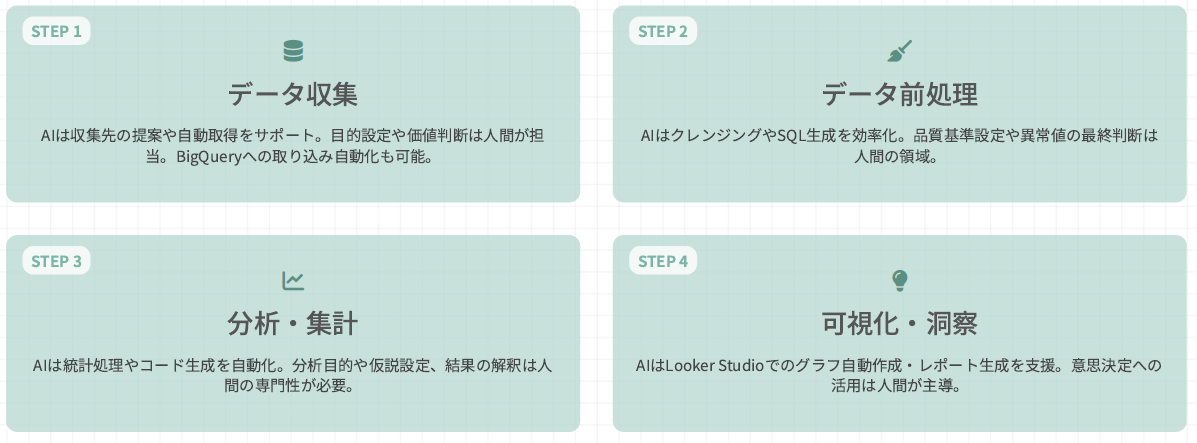
ステップ1. データ収集
分析前のデータ収集を行うフェーズです。
【AIの役割】
収集先の提案や自動取得をサポート、またBigQueryへの取り込み自動化も可能です。
【人間の役割】
データ収集における、目的設定や価値判断を行います。
ステップ2. データ前処理
収集したデータの前処理を行います。
【AIの役割】
データのクレンジングやSQL生成を効率化します。
【人間の役割】
品質基準の設定や異常値の最終判断を担います。
ステップ3. 分析・集計
収集したデータの分析や集計を行うフェーズです。
【AIの役割】
統計処理やコード生成を自動化します。
【人間の役割】
分析目的や仮説設定、結果の解釈を行います。
ステップ4. 可視化・洞察
分析したデータの可視化・洞察を行うフェーズです。
【AIの役割】
Looker Studioでのグラフ自動作成・レポート生成を支援します。
【人間の役割】
意思決定へのデータ活用を担います。
②AIの得意なこと vs 苦手なこと
上記の役割分担をまとめると、AIは反復・自動生成に強いが、文脈理解は不得意です。
以下はAIの得意なことの一例です。
- 大量データの高速処理と分析
- パターン認識とデータからの相関関係の発見
- 単調で繰り返しの多い作業の自動化
- SQL、プログラミングコードの生成と修正
- テキスト要約と類似表現のバリエーション生成
【実践例】
例えば、AIがBigQueryでの複雑なSQLクエリ生成や最適化を支援する場合、数百行のコードを数秒で提案し、データアナリストの作業時間を削減します。また、レポート文章のドラフト作成や翻訳作業も大幅に効率化することができます。
反対に、AIの苦手なことは以下のようなものです。
- ビジネス固有の文脈や背景の深い理解
- データの品質評価や信頼性の判断
- 分析結果の「意味」や「重要性」の評価
- 組織としての戦略的意思決定やKPI設定
- データに存在しない創造的な問題解決方法の提案
【注意点】
上記のケースでAIを活用する際、AIの提案はあくまで参考材料であることに留意し、最終的な判断は常に人間が行う必要があります。特に、顧客データの解釈や売上予測の妥当性評価などでは、業界知識や経験に基づく人間の洞察が不可欠です。
【実践例:BigQueryでのN=1顧客分析】
BigQueryとAIを組み合わせた個別顧客分析の新しいアプローチとして、BigQueryとGeminiを連携させることで、顧客一人ひとりの行動を効率的に分析し、示唆抽出に集中できるワークフローを実現した事例をここでご紹介します。
従来の顧客データ分析では、大量のテキストデータからの洞察抽出に多くの時間を費やしていました。また、N=1分析は顧客一人一人のデータを分析するため、データが比較的軽量かつ容易である一方、営業部などからのクイックなリクエストに応えるには十分なエンジニアリソースが必要で、多くの場合リソースのマッチングが難しく、タイムリーな分析が困難でした。
この課題に対し、BigQueryMLのテキスト生成関数(API経由でGeminiが動作)を活用し、ユーザーIDを入力するだけで顧客の興味・関心や商談準備事項を自動出力するダッシュボードを構築しました。結果、エンジニアに依頼することなく、営業担当者が直接必要な顧客洞察を得ることができるようになりました。
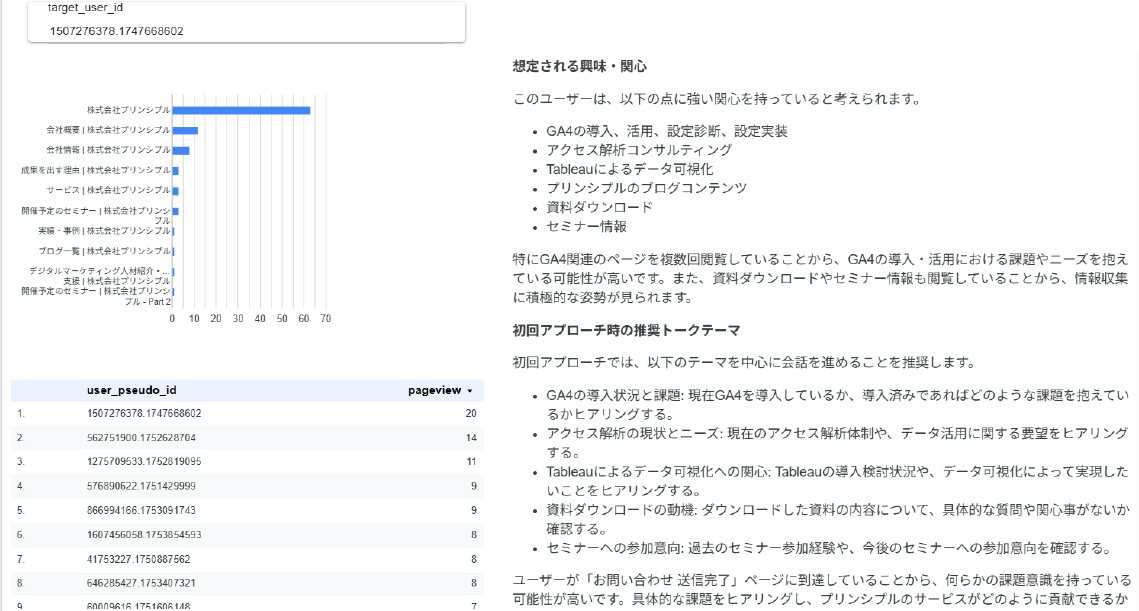
以下はプリンシプルに問い合わせしてきたユーザーのページ閲覧を表したグラフです。
3. データマート構築と組織の意思決定
①データマート構築の利点
データ分析AI活用において、データマート構築は重要な要素です。データマートとは組織共通の尺度を決める基盤で、これを構築することで業務の指標を統一できます。
以下にデータマート構築の利点をまとめました。
- 組織全体での一貫した定義の共有
部門ごとに異なる指標や集計方法がある状態から、全社共通の定義を整備することができます。 - 業務KPIとデータの紐付け明確化
ビジネス目標とデータ分析を結びつけるデータモデルを構築し、意思決定の基盤となります。 - データマート構築による再利用性向上
共通の定義に基づいたデータマートを活用することで、分析作業の重複防止と効率化を実現します。 - 複数データソースの整合性確保
異なるシステムからのデータを統合する際の変換ルールを明確にし、一貫性のある分析基盤を構築します。 - 信頼できる単一の情報源(SSOT)確立
組織内での「正しい数字」の拠り所を作り、データに基づく議論や意思決定の質を向上します。
データマートの構築によりデータの定義をAI に伝えることで、組織全体で同じ定義のデータを使える状況を実現します。
②生成AIにはできない定義づけ
一方で、「KPIの定義づけ」は人と組織の合意が不可欠です。
特に、多部門間の利害調整と合意形成プロセスはAIに任せることが難しく、各部門の視点を理解し、時に相反する利害関係を調整してKPI定義に合意を得る複雑なコミュニケーションが求められます。
以下は、生成AIにはできない定義づけの具体例です。
- 組織の戦略的目標に基づくKPI設計
企業のビジョンや中長期計画との整合性を考慮した指標設計は、AIではなく経営層・事業責任者が担うべき役割です。 - 多部門間の利害調整と合意形成プロセス
各部門の視点を理解し、時に相反する利害関係を調整してKPI定義に合意を得る複雑なコミュニケーションは生成AIにはできません。 - ビジネスコンテキストの深い理解と反映
業界特性、競合状況、市場環境などのコンテキストを踏まえたKPI設計には人間の経験値が不可欠です。 - 定義の継続的進化と意味づけの調整
ビジネス環境の変化に応じてKPI定義を更新し、組織内で再合意を形成する持続的なガバナンス活動は人間が担当します。 - 定性的判断と倫理的考慮の統合
数値だけでは測れない価値や、社会的責任を含めた総合的判断をKPI体系に組み込む人間固有の価値判断は生成AIでは実行不可能です。
【ケーススタディ:売上定義の違いによる混乱の事例】
ある大手小売企業では、同じ「売上金額」という言葉に対して、営業部門は「受注金額」、経理部門は「入金済み金額」、マーケティング部門は「返品・キャンセル除外後の金額」とそれぞれ異なる定義で業務を行っており、部門間で異なる「売上」定義がされていました。
経営会議で「売上20%増」という目標が掲げられた際、各部門が異なる定義で目標設定・進捗管理を行ったため、整合性のない報告が行われ、データの定義の違いに議論が終始することで、意思決定が遅れました。
発生した問題
- 同じKPI名でも部門ごとに計算方法が違う
- 会議で数字の議論に多くの時間を消費
- データソースの信頼性が低下
- 意思決定の遅延・誤りが発生
このような問題の解決には、データマートで正式な「売上」定義を明文化し、ビジネス用語集で定義を統一することなどが必要です。
解決策
- データマートで正式な「売上」定義を明文化
- ビジネス用語集で定義と計算方法を共有
- 全社統一KPIダッシュボードの構築
- 部門特有の集計はオプション指標として区分
4. データガバナンスの重要性
①データガバナンスとは
データマート構築に加え、データガバナンスはデータ品質・意味・責任を守る仕組みで、AI時代のデータ活用で大事にすべき要素です。
以下はデータガバナンスの具体例です。
- 組織全体のデータ管理とルール策定の体系
データの収集から活用、廃棄までを組織的に管理するためのフレームワークと実践を行います。 - データ品質の確保とメンテナンス
正確性・完全性・一貫性・適時性など、信頼できるデータの特性を維持する仕組みを構築します。 - セキュリティとプライバシーの保護
機密データの適切なアクセス制御と、個人情報保護法などの法令を遵守します。 - データ定義とメタデータ管理
データの意味や関係性を明確化し、組織全体で共通理解を構築するための体制を整えます。 - 意思決定の信頼性向上と価値創出
高品質なデータに基づく意思決定を促進し、データ資産から最大価値を引き出す基盤を構築します。
②ガバナンスに必要な要素
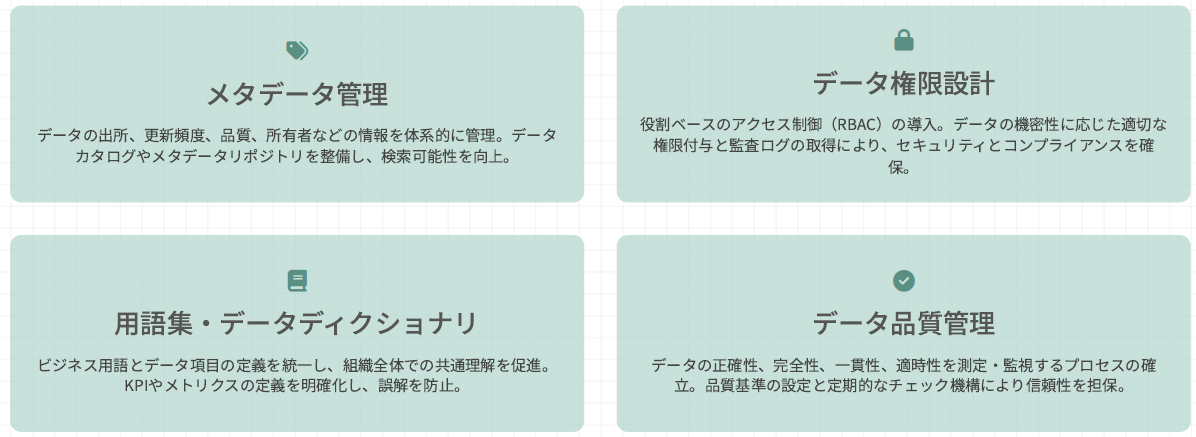
効果的なデータガバナンス実現のためには、組織全体でデータ品質と一貫性を確保する仕組みが不可欠です。特に、メタデータ・権限・用語集はデータ活用の土台となります。
以下、4つの要素はデータ活用成功の基盤となります。
- メタデータ管理
- データ権限設計
- 用語集/データディクショナリ
- データ品質管理
③データ活用を支える組織づくり
組織でデータを有効活用するには、単にルールを作ったり、ツールを導入するだけでは不十分で、組織全体で役割分担を明確にすることが大切です。特に、データを日々使う現場チームと、データの品質を守る管理部門の協力が成功の鍵となります。
以下に、現場チームと管理部門の役割をまとめました。
【現場チームの役割】
- 日々のマーケティングデータの入力と活用
- 現場視点での情報提供
- 指標の定義確認
- 改善提案
【データ管理部門の役割】
- 全社共通の「データの定義」の決定
- データの保存場所の整理
- データの品質チェックと改善
- 現場向けの使い方ガイダンスと勉強会
このように、各部門の役割が異なる状況においてデータ活用がうまくいく組織では、経営層からの方針と現場からの改善アイデアが循環する仕組みが重要です。
特に「データ品質担当者」が現場とデータ管理部門の間で通訳のような役割を果たすことで、「作ったけど誰も使わない」という状況を防ぎ、継続的に活用される環境を実現できます。
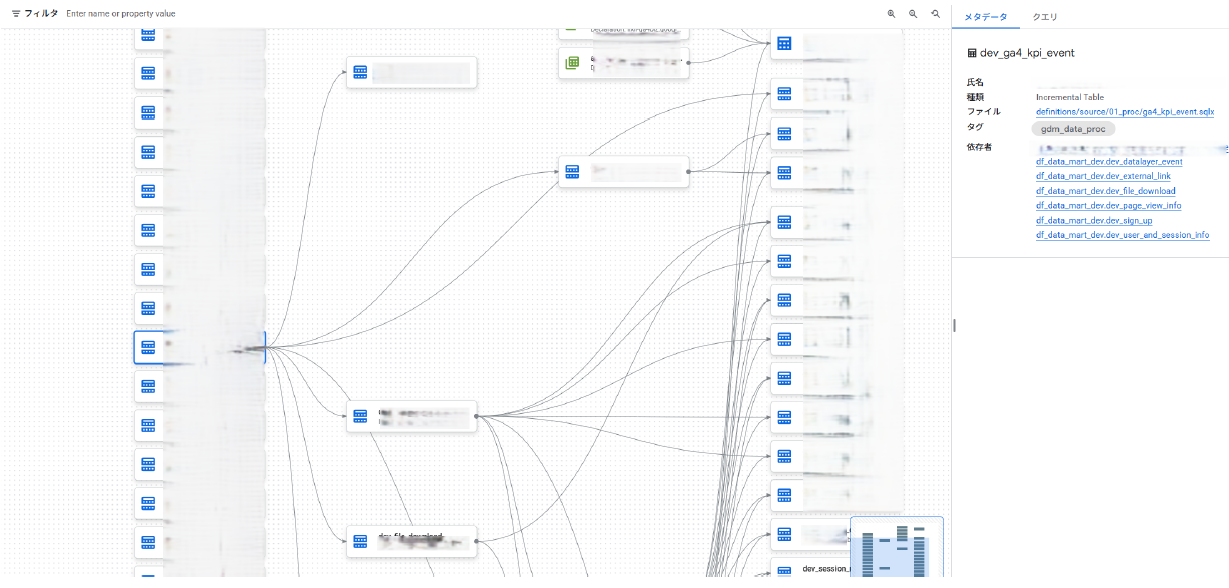
【実践例:Google Dataformでのパイプライン管理】
コードとしてのデータ定義による品質管理と透明性の確保を目標に、Dataformで透明性・再現性・品質を担保した事例です。
Google Dataformは、SQLをベースとしたデータパイプライン管理ツールです。データ変換プロセスを宣言的に記述・バージョン管理することで、データ処理の透明性が高まり、チーム間での知識共有や変更履歴の追跡が容易となります。
以下は、大手ECサイトでのDataform活用事例です。
- SQLファイルとして定義し一元管理(GitHub連携可)
- テーブル間の依存関係を明示的に定義し処理順序を自動制御
- テーブルの品質チェック(null値・重複確認)を組込み
- 動的SQLで一つのコードから複数テーブル作成し保守性強化
Dataform活用メリットは以下3つです。
- コードによるデータパイプライン定義による再現性の向上
- 依存関係の自動管理でエラー減少 ・品質チェック自動化でデータ信頼性の確保
- 変更履歴追跡で安全な修正と拡張性の向上
結果、データパイプラインのエラー率が大幅減少し、新規分析基盤の構築リードタイムが従来の1/10に短縮しました。また、データマートとダッシュボードの汎用化により、各部門での活用が促進されました。
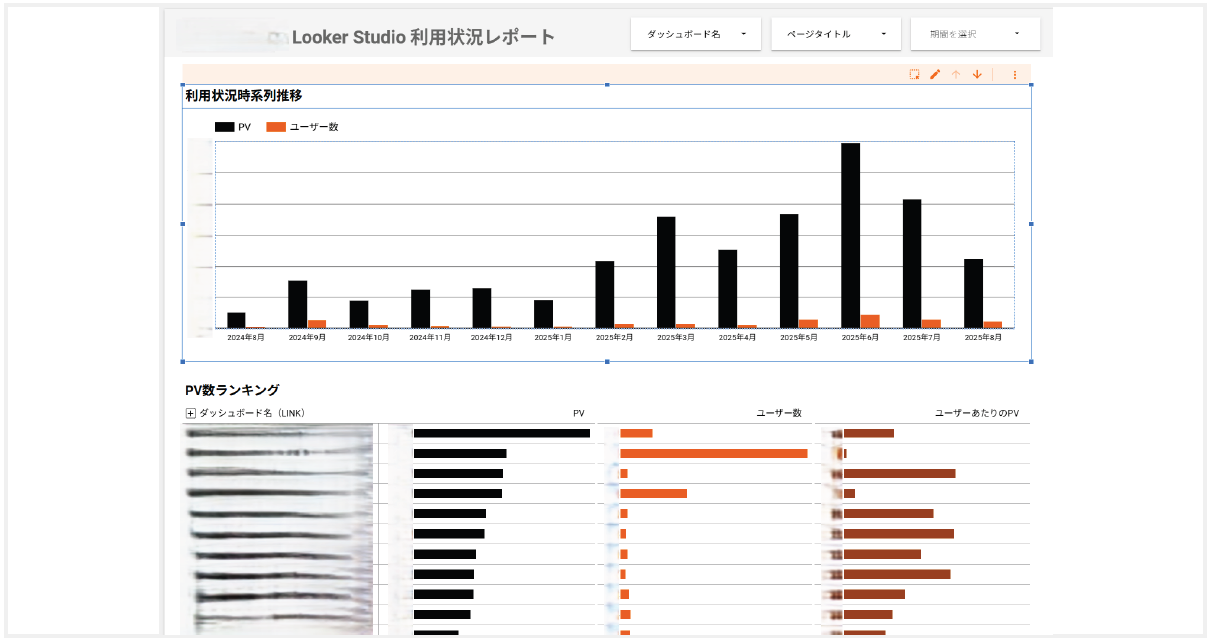
【実践例:Looker Studio利用状況監視ダッシュボード】
取り組み内容は、組織内のLooker Studio活用状況を可視化し、継続的な改善を支援するダッシュボードの作成です。
背景として、複数のユーザーにLooker Studioの作成権限を解放した結果、ユーザーが自由にダッシュボードを作成できる反面、大量のダッシュボードが乱立し、データ利用の現状把握が困難なことが課題としてありました。
そこで、以下のダッシュボードを作成し、Looker Studioの月別利用状況(PV数・ユーザー数)の推移と、個別ダッシュボードのPVランキングを一目で確認できるようにしました。また、各ダッシュボードのURLが埋め込まれているため、即座に対象のダッシュボードにアクセス可能です。
結果、 アクセス数の少ないダッシュボードを特定し、改善または統廃合の判断材料としてのダッシュボード活用を実現しました。さらに、類似したダッシュボードを特定し一元管理することで、「Single Source of Truth(唯一の信頼できる情報源)」も確立しました。
5. キーメッセージ
①「AI任せ」と「AI活用」の線引き
生成AIは共創ツールであり意思決定者ではないことを理解することが重要です。特に「AI任せ」と「AI活用」には明確な線引きがあります。例えば選択肢の生成はAIに任せられますが、組織の意思決定は常に人間が組織の価値観に基づいて行う必要があります。
以下の5つのポイントを抑えましょう。
- AIの得意分野と役割を正しく理解する
生成AIは情報処理と提案に優れるが、価値判断や責任の所在を定めることは不可能です。 - 「AI任せ」と「AI活用」の明確な線引き
選択肢の生成はAIに、最終選択と判断基準の設定は人間の領域として区分けすることが重要です。 - 組織の意思決定プロセスにおけるAIの位置づけ
AIの提案は「参考意見」として扱い、最終判断は常に人間が組織の価値観に基づいて行いましょう。 - 人間とAIの相互学習サイクルの構築
AIの提案から学び、人間がフィードバックを与えることで共に成長する関係性の構築が必要です。 - 責任の所在を明確化したガバナンス体制
AIによる分析結果の採用判断と結果責任は常に人間側にあることを組織内で明文化しましょう。
②成功のカギ
データ分析における生成AI活用の成功のカギは、生成AIの可能性と限界を理解し、一般教育と専門人材の育成を並行して進めることが重要です。
以下は生成AIを使いこなす組織になるための具体例です。
- 全社的なAIリテラシー向上と技術者育成の両立
生成AIの可能性と限界を理解する一般教育と専門人材の育成を並行して進めましょう。 - 組織横断的なデータガバナンス体制の構築
現場と統括部門が協働し、データの品質と活用を両立する明確なルールと責任体制の確立が重要です。 - 段階的な導入と小さな成功体験の積み重ね
大規模変革ではなく、小さく始めて効果を実感しながら徐々に適用範囲を拡大しましょう。 - トップダウンとボトムアップの相互連携
経営層の理解・支援と現場からの改善提案を結びつけ、組織全体の変革を推進する仕組みが大切です。 - 継続的な学習と改善のサイクル確立
技術と活用法の進化に合わせて定期的に振り返り、組織のAI活用力を持続的に向上させる体制を構築しましょう。
6. まとめ
この記事では、2025年8月26日に開催したウェビナー「生成AI活用データ分析術〜BigQuery・Looker Studioと生成AIで実現する、示唆だし自動化の実践法〜」を元に、BigQuery・Looker Studioに蓄えられたデータから生成AIを活用して示唆を抽出するための実践的な知見について解説しました。
◼︎こんな方におすすめ
- BigQueryにデータを蓄積しているが、示唆を得るための分析に時間がかかりすぎている方
- 生成AIをデータ分析に試したが、表層的なアウトプットしか得られず、結局は人手で再分析している方
- BigQueryのデータを、生成AIを使ってさらに高度に分析したい方
また、弊社ではBig QueryやLooker Studioに関するご支援を多数行っております。お困りごとがある際は、いつでもお気軽にお問い合わせください。