Tableauはさまざまな拡張性を秘めています。TabPyを使用することで、従来の可視化という手段に加えて、統計分析の手法を用いて分析を行うことが可能になります。
この記事では、TabPyの概要や実装方法について解説します。そして機械学習の練習用データとして有名であるタイタニック号のデータを使用して、TabPyを通した分析を行います。
免責事項
当サイトのコンテンツ・情報につきましては、可能な限り正確な情報提供に努めておりますが、その正確性および安全性を保証するものではございません。情報が古くなっている場合もございます。また、掲載しているプログラムコードはあくまでサンプルです。実際にご利用いただく際は、前処理を含めてご自身でコードをご記述いただくことを推奨いたします。
本ブログで紹介している TabPy には、セキュリティ上の注意点がございます。ご利用にあたっては、詳細を十分にご確認のうえ、ご判断ください。
当サイトに掲載された内容により生じた損害等につきましては、一切の責任を負いかねますので、あらかじめご了承ください。
TabPyとは何なのか
TableauのDeveloper Programポータルには次のように記載されています。
TabPy (Tableau Python Server) は、ユーザーが Tableau の表計算を介して Python スクリプトと保存された関数を実行できるようにすることで Tableau の機能を拡張する、分析拡張機能の実装です。
- TabPyは分析を拡張する機能である。
- Tableauから変数をTabPy Serverへ渡すことで、TabPy Serverから出力結果を受け取る。
- TabPyに事前作成した関数を、Tableau上から利用する。
ユーザーはTableauのダッシュボード、ワークシート等を操作することで、TabPyに送信されるデータやパラメーターを制御できるため、Pythonのコードをリアルタイムで実行し結果を得ることができます。
※TabPyの重要なセキュリティに関する注意事項がありますので、詳細は以下をご確認ください。
TabPy Server Configuration Instructions
TabPyの簡単な実装手順
TabPyを利用するには、Pythonの開発環境をお持ちであることが前提となります(お持ちでない方はインストールし設定しておくことをお勧めします)。
コマンドプロンプトやターミナル、Powershellなどで以下を入力してインストールされているバージョンが表示されることを確認してください。
python --version
ここから今回の目的を達成するためのライブラリをインストールし、TableauとTabPy Serverの接続を行っていきます。
手順① ライブラリのインストール
以下のコードから、今回の検証で用いるライブラリをインストールします。
pip install statsmodels pandas scikit-learn
- statsmodels:回帰分析や時系列分析、検定など幅広い統計手法を提供する統計解析ライブラリの一つです。
- pandas:データを操作するためのライブラリです。
- scikit-learn:データ分析や機械学習(学習、予測、モデルの評価などなど)を行うためのライブラリです。
手順② TabPyのインストール・起動
Pythonが使える状態で、以下のコードよりTabPyパッケージをインストールします。
pip install tabpy
インストール完了後、以下のコマンドでTabPyを起動していきます。
tabpy
ログが走り、TabPyが実行状態となります。この時、ポート番号が9004であることを確認します。

※追加でライブラリをインストールするなど、TabPyを終了させたい場合は「Ctrl+C」をコマンド上で入力します。
手順③ Tableau DesktopとTabPy Serverの接続テスト
ヘルプ>設定とパフォーマンス>分析の拡張機能の接続管理 をクリックします。
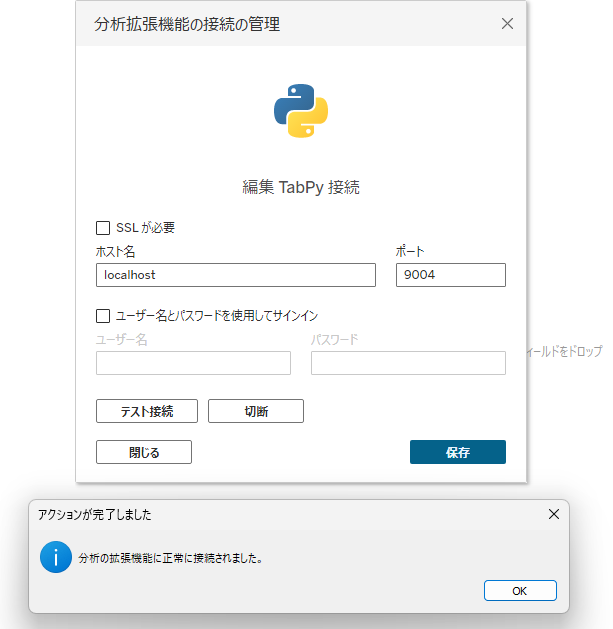
ホスト名とポートが画像の通りであることを確認したら、テスト接続をクリックします。「分析の拡張機能に正常に接続されました」と表示されましたら、「保存」をクリックしてテストは完了です。
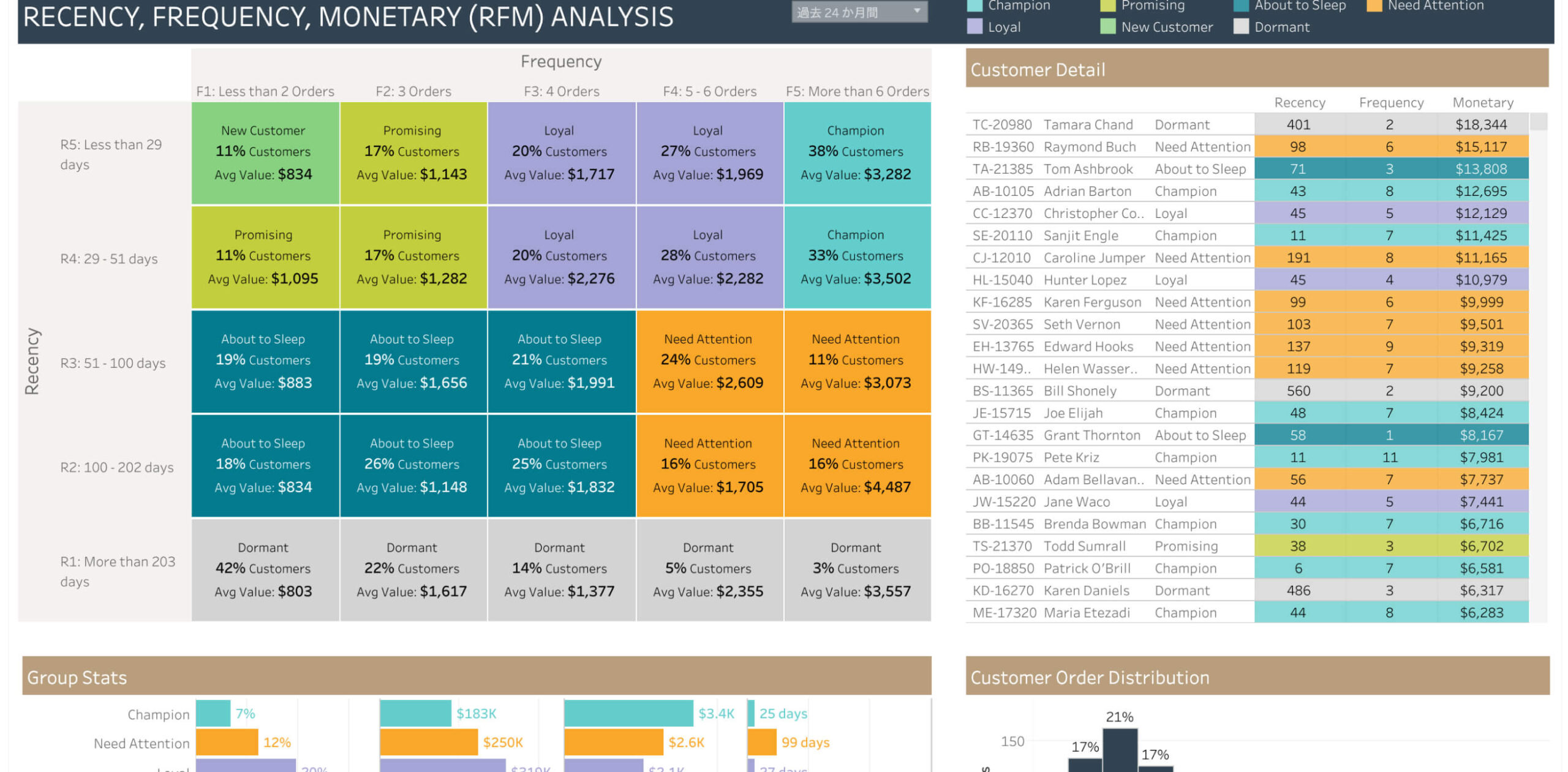
今回の目的と、データの紹介
本ブログの目的は、TabPyを使用して標準機能には無い分析を実行してみることにあります。今回は、Kaggle(世界中の機械学習を学習する人々が交流するプラットフォーム)に初心者向けコンペとして存在する、タイタニック号のデータを用いて分析を実行します。
Kaggle内で展開されるタイタニックコンペは登竜門的な立ち位置であり、タイタニック号の難破事故で生存した乗客を、情報(年齢、性別、class…)から予測するモデルを作成します。
Titanic – Machine Learning from Disaster | Kaggle
Kaggleのデータ(タイタニック号乗客の生存情報)について
詳細なデータは実際に確認いただければと思いますが、簡単に紹介いたします。
Trainデータの、最初のデータを確認すると891行12列あることが分かります。
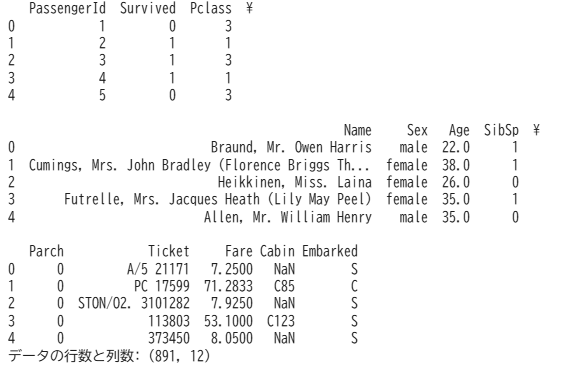
それぞれの列の意味は以下になります。
- PassengerId:乗客識別ユニークID
- Survived:生存フラグ(0=死亡、1=生存)
- Pclass:チケットクラス(1=1st,2=2nd,3=3rd)
- Name – 乗客の名前
- Sex – 性別(male=男性、female=女性)
- Age – 年齢
- SibSp – タイタニックに同乗している兄弟/配偶者の数
- parch – タイタニックに同乗している親/子供の数
- ticket – チケット番号
- fare – 料金
- cabin – 客室番号
- Embarked – 出港地
採用するライブラリとモデル(Logistic Regression)
タイタニック号乗客の生存(= 0死亡、1生存)について説明を試みることが目的ですので、2つの状態の内一方が起こる確率、説明に用いた変数が確率にどの程度影響しているのかを探索分析します。(※本ブログでは回帰係数の導出を行います。確率を求めるにはトレーニングデータとテストデータを分け、モデルをデプロイするなど別行程を取ります。)
生存フラグに影響を与える変数を探索するために、ロジスティック回帰を採用します。
- Pythonから利用できるライブラリ(scikit-learn)を採用
- モデル:LogisticRegressionを採用()
- 目的変数:Survived_生存フラグ(0=死亡、1=生存)
- 説明変数:'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'
モデルの詳細な説明は割愛させていただきます。
分析の実装手順
以下の手順でコードを構築していきます。
- 1. 説明変数(X)と目的変数(Y)の定義
- 2. 前処理(欠損値埋め、ワンホットエンコーディング)の実施
- 3. 結果の表示
実際に使用するコードの紹介:前処理と回帰係数の導出
TabPyにていきなり結果を出力する前に、まずはPython上で結果を確認しながら実行します。その後TabPy用のスクリプトとしてTableauに表示させます。
はじめに、必要なライブラリを「インポート」します。
# ライブラリのインポート
import pandas as pd
import numpy as np
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
import sys # エラー出力用 (任意)
次に、説明変数(X)と目的変数(Y)の定義づけを行います(Cabin , Name , Ticketは前処理が複雑なので説明変数から除外します)。
# 説明変数 (X) と目的変数 (y) を定義
feature_cols = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
target_col = 'Survived'
printで確認すると以下の様子です。
次に、欠損値の存在は無視できませんので欠損値(Null)の確認を行います。同時にデータ型も確認します。
if 'df_titanic' in locals():
feature_cols = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
X = df_titanic[feature_cols].copy() # 元のDataFrameから特徴量列をコピー
print("--- 元のデータ (X) の最初の5行 ---")
print(X.head())
print("\n--- 元のデータ (X) の欠損値情報 ---")
print(X.isnull().sum())
print("\n--- 元のデータ (X) のデータ型情報 ---")
print(X.info())
else:
print("エラー") #エラー時に返す
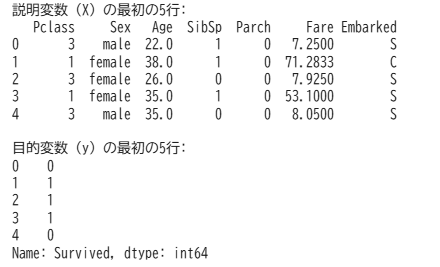
結果として以下の通りになりました。
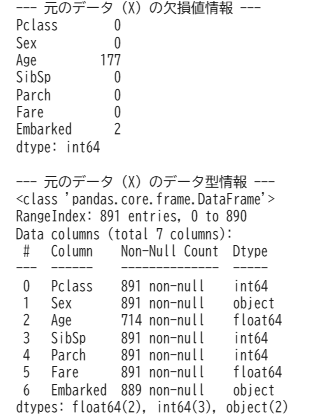
Nullが存在するカラムは、Age(年齢)、データ型は、float64が2列、int64が3列、objectが2列だということが分かりました。また、このタイミングで平均値や中央値、標準偏差などの基本統計量も確認しておくとデータ全体を解釈しやすいです。
今回は、数値型の列とカテゴリカルの列において、欠損値に対する補完と前処理を変えて実行します。
数値型列の前処理
欠損値:各列の中央値で補完
前処理:各変数を標準化(平均0、標準偏差1になるように変換)します。これにより、スケールの異なる特徴量の影響度合いをモデルが評価しやすくなります。
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import pandas as pd
if 'X' in locals():
numeric_features = ['Age', 'SibSp', 'Parch', 'Fare', 'Pclass']
# 1. 数値特徴量のみを対象としたImputerを定義
numeric_imputer = SimpleImputer(strategy='median')
X_numeric_imputed_array = numeric_imputer.fit_transform(X[numeric_features])
X_numeric_imputed_df = pd.DataFrame(X_numeric_imputed_array, columns=numeric_features, index=X.index)
# 2. ImputerとScalerを含む数値特徴量全体のパイプラインを定義
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
X_numeric_transformed_array = numeric_transformer.fit_transform(X[numeric_features])
X_numeric_transformed_df = pd.DataFrame(X_numeric_transformed_array, columns=numeric_features, index=X.index)
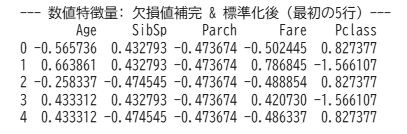
SimpleImputer(strategy='median')で中央値による補完を行います。そして、StandardScaler()で各変数を標準化します。すると以下のような形になります。
カテゴリカル列の前処理
欠損値:各列の最頻値で補完
前処理:ワンホットエンコーディングを実施します。これにより、モデルが理解しやすいように数値データに変換(ダミー変数化)します。
from sklearn.preprocessing import OneHotEncoder
if 'X' in locals():
categorical_features = ['Embarked', 'Sex']
# 1. カテゴリカル特徴量のみを対象としたImputerを定義
categorical_imputer = SimpleImputer(strategy='most_frequent')
X_categorical_imputed_array = categorical_imputer.fit_transform(X[categorical_features])
X_categorical_imputed_df = pd.DataFrame(X_categorical_imputed_array, columns=categorical_features, index=X.index)
# 2. ImputerとOneHotEncoderを含むカテゴリカル特徴量全体のパイプラインを定義
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore', drop='first'))
])
X_categorical_transformed_array = categorical_transformer.fit_transform(X[categorical_features])
try:
X_categorical_transformed_array = X_categorical_transformed_array.toarray()
except AttributeError:
pass # 既にNumpy配列の場合は何もしない
ohe_feature_names = categorical_transformer.named_steps['onehot'].get_feature_names_out(categorical_features)
X_categorical_transformed_df = pd.DataFrame(X_categorical_transformed_array, columns=ohe_feature_names, index=X.index)
SimpleImputer(strategy='most_frequent')で最頻値となるよう補完を行います。さらに、OneHotEncoder(handle_unknown='ignore', drop='first')でダミー変数化を行います(最初のカテゴリに対応する列を削除しています)。
その結果、以下のような該当するカラムには1というフラグがつく形になります。

ここまで完了すれば、あとは実際に回帰係数の導出を行い、結果を確認します。
(※仮に予測を実施する場合は、以下をコードに組み込みます。)
学習にはfitメソッドを使用し、予測をclf.predict_proba(X)[:, 1]にて行います。
学習:clf.fit(X, y)
予測:clf.predict_proba(X)[:, 1]
回帰係数の導出
各説明変数(特徴量)ごとに係数を算出するために、以下のコードを実行します。
# clf (パイプライン) が正しく定義されているか確認
if 'clf' in locals() and 'X' in locals() and 'y' in locals():
try:
# --- モデル学習 ---
clf.fit(X, y)
# --- 係数と特徴量名の取得 ---
log_reg_model = clf.named_steps['classifier']
fitted_preprocessor = clf.named_steps['preprocessor']
transformed_feature_names = fitted_preprocessor.get_feature_names_out()
coefficients = log_reg_model.coef_[0] # ロジスティック回帰の係数
# 特徴量名と係数を表示
feature_coeffs_dict = {}
for name, coeff in zip(transformed_feature_names, coefficients):
print(f"{name}: {coeff:.4f}")
feature_coeffs_dict[name] = coeff
結果として以下になりました。

一連の作業をTabPyを通して、Tableauに値を表示する
これまで、前処理から係数導出までPython上で確認しました。ここからは実際にTabPyを通して値を取得したいと思います。
TabPyと接続したTableau Desktopを立ち上げます。
計算フィールド内に「SCRIPT_」から始まる関数を入力し、コードを記述します。プログラムの計算結果のデータ型に応じて、下記4種類の関数を切り替えます。
- SCRIPT_INT()・・・戻り値が整数
- SCRIPT_STR()・・・戻り値が文字
- SCRIPT_BOOL()・・・戻り値がBoolean(TrueかFalse)
- SCRIPT_REAL()・・・戻り値が小数
今回は、説明変数と係数を”|”でつなぐことで文字列型としてViz上に表示します。
下記のコードをTableauの計算フィールド内に記述します。
計算フィールド名は「Feature Importances (Logistic Regression)」
SCRIPT_STR(
"
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
import sys
import io # 文字列結合用
default_return_value = 'Error: Calculation failed'
try:
# Tableauからの引数 (_arg1 は PassengerId の想定)
pclass = _arg2
sex = _arg3
age = _arg4
sibsp = _arg5
parch = _arg6
fare = _arg7
embarked = _arg8
survived = _arg9
df = pd.DataFrame({
'Pclass': pclass, 'Sex': sex, 'Age': age,
'SibSp': sibsp, 'Parch': parch, 'Fare': fare,
'Embarked': embarked, 'Survived': survived
})
feature_cols = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
target_col = 'Survived'
X = df[feature_cols]
y = df[target_col]
if X.empty or len(y.unique()) < 2:
return [f'Error: Insufficient data (rows: {len(X)}, unique_targets: {len(y.unique())})'] * len(_arg1 if _arg1 is not None and hasattr(_arg1, '__iter__') else X)
# --- 前処理の定義 ---
numeric_features = ['Age', 'SibSp', 'Parch', 'Fare', 'Pclass']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_features = ['Embarked', 'Sex']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore', drop='first'))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
],
remainder='passthrough'
)
# --- モデル定義 ---
model = LogisticRegression(solver='liblinear', random_state=42)
clf = Pipeline(steps=[('preprocessor', preprocessor), ('classifier', model)])
clf.fit(X, y)
# --- 係数と特徴量名の取得 ---
log_reg_model = clf.named_steps['classifier']
fitted_preprocessor = clf.named_steps['preprocessor']
# 変換後の特徴量名を取得
transformed_feature_names = fitted_preprocessor.get_feature_names_out()
# 係数を取得 (ロジスティック回帰はクラスが2つの場合、coef_ の形状は (1, n_features))
coefficients = log_reg_model.coef_[0]
# 特徴量名と係数をペアにする
feature_coeffs = list(zip(transformed_feature_names, coefficients))
# 文字列として整形 (例: 'Feature1:0.567|Feature2:-0.432|...')
output_string = io.StringIO()
for i, (name, coeff) in enumerate(feature_coeffs):
output_string.write(f'{name}:{coeff:.4f}')
if i < len(feature_coeffs) - 1:
output_string.write('|')
result_str = output_string.getvalue()
list_length = len(_arg1 if _arg1 is not None and hasattr(_arg1, '__iter__') else X)
return [result_str] * list_length
except Exception as e:
error_message = f'Error: {str(e)}'.replace('|',';').replace(':',';') # 区切り文字衝突回避
list_length = len(_arg1 if _arg1 is not None and hasattr(_arg1, '__iter__') else X) # Xが未定義の可能性も考慮
try:
list_length_final = len(_arg1 if _arg1 is not None and hasattr(_arg1, '__iter__') else X)
except NameError: # Xも未定義の場合
list_length_final = 1
return [error_message] * list_length_final
",
// --- Tableauからの引数 (順番をPythonコード内の _argX と一致させる) ---
ATTR([Passenger Id]), // _arg1
ATTR([Pclass]), // _arg2
ATTR([Sex]), // _arg3
ATTR([Age]), // _arg4
ATTR([Sib Sp]), // _arg5
ATTR([Parch]), // _arg6
ATTR([Fare]), // _arg7
ATTR([Embarked]), // _arg8
ATTR([Survived]) // _arg9: モデル学習の正解データ
)
ここで作成した計算フィールドを実際にTableau上のラベルにプロットしてみます。
説明変数と係数が表示されました。
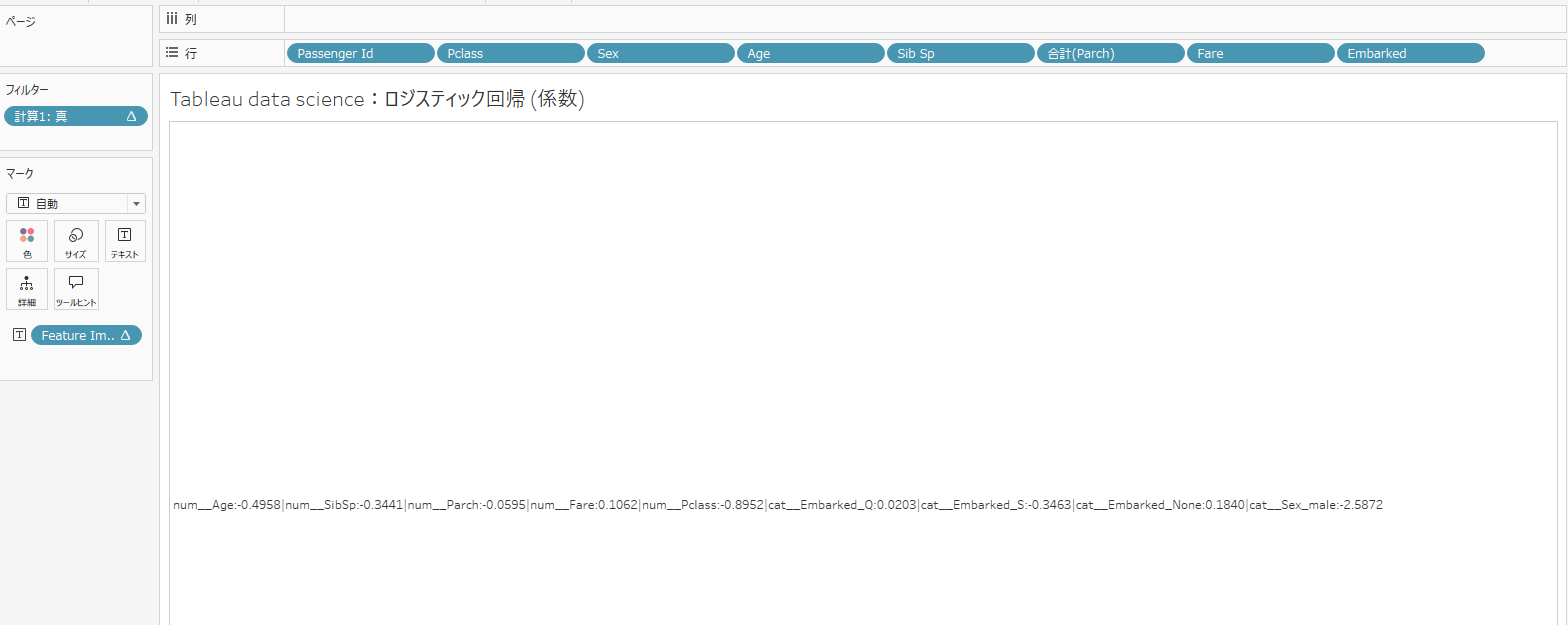
以下のような結果になりました。
num__Age:-0.4958|num__SibSp:-0.3441|num__Parch:-0.0595|num__Fare:0.1062|num__Pclass:-0.8952|cat__Embarked_Q:0.0203|cat__Embarked_S:-0.3463|cat__Embarked_None:0.1840|cat__Sex_male:-2.5872
これらの係数は各説明変数(特徴量)が、「生存」にどれほど影響を与えているかを示します。中でも注目したい特徴量は性別 (cat__Sex_male)、客室クラス (num__Pclass)、年齢 (num__Age)です。
■性別 cat__Sex_male: -2.5872
- 男性であることは、女性であることと比較して生存対数オッズを約2.5872減少させます。
- オッズ比:exp(-2.5872) = 0.075230390550789であることから、条件が同じであるならば、男性の生存オッズは女性の約0.075倍。
■客室クラス num__Pclass: -0.8952
- 値が1標準偏差分増加する(ここでは下級クラスに移る)と、生存対数オッズが0.8952下がります。
- 性別に次いで影響が大きいとみられる変数。
■年齢 num__Age: -0.4958
- 値が1標準偏差分増加する(ここでは年齢が大きくなる)と、生存対数オッズが0.4958下がります。
- 客室クラスに次いで影響が大きいとみられる変数。
まとめると、男性であること、客室クラスが低いこと、高齢であるほどに生存に不利であったと考えることができます。あくまで係数のみでの考察ですが、P値等他指標と合わせることでより深い考察が可能になります。
おまけ
前述のとおり、予測モデルを用いて生存確率を算出できます。算出した確率を Tableau 上で色分けして表示すると、視認性が大きく向上します。さらに、可視化された確率情報をもとに、一定の閾値を超えた ID に対してアクションを検討することも可能です。
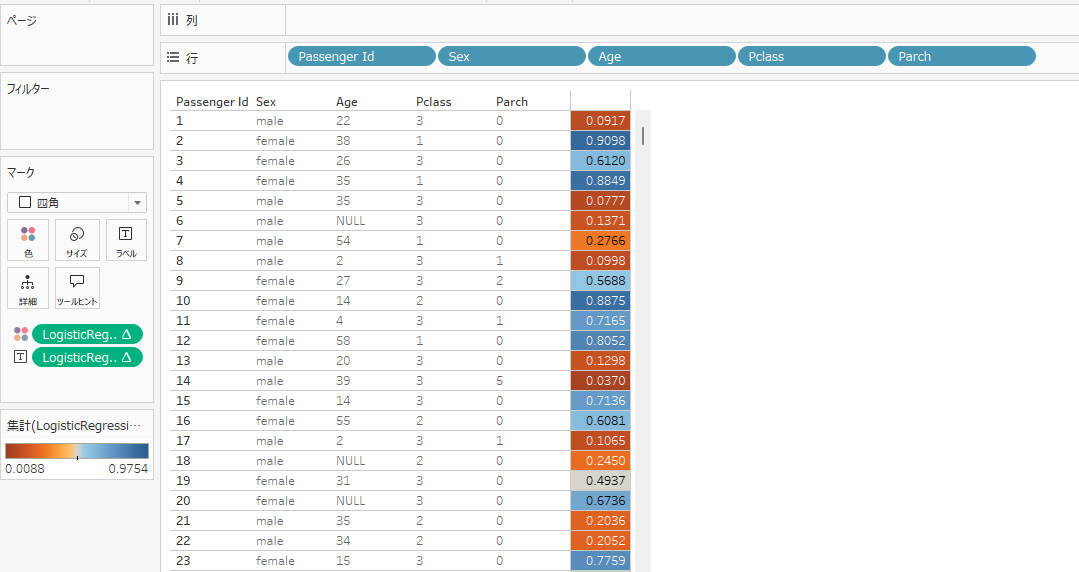
まとめ:TabPyを通してできることとは?
この記事では、TabPyの概要や実装方法について解説し、そしてTabPy を活用してロジスティック回帰分析を実行しました。
Python のライブラリを利用することで、多様な手法を取り入れることが可能です。今回導入したロジスティック回帰モデルを応用すれば、例えば「サービス紹介ページが、問い合わせにつながるか」といった、コンバージョンの有無に関する分析ができます。
また、クラスター分析や顧客の解約予測、テキストデータを対象としたセンチメント分析なども実装可能です。
TabPy を導入することで、Tableau の表計算を通じて Python のスクリプトや関数を実行し、分析機能を大きく拡張できます。集計したデータをさらに深掘りし、データサイエンスの世界へ一歩踏み出してみましょう。
参考ページ
- TabPy
- TabPy | Execute Python code on the fly and display results in Tableau visualizations:
- SimpleImputer — scikit-learn 1.6.1 documentation
- TabPyの実装方法3ステップ【初心者向け】
- Titanic – Machine Learning from Disaster | Kaggle