Google CloudのデータウェアハウスであるBigQuery。その高速なクエリ性能とスケーラビリティから、多くの企業でデータ分析基盤として活用されています。日々進化を続けるBigQueryは、その機能を最大限に活用することで、データ活用の可能性はさらに広がります。
この記事では、2025年度上半期に一般公開(GA)となったBigQueryのアップデートの中から、特にデータ分析の現場ですぐに役立つ重要な機能10個を厳選し、その概要を紹介します。
1. パイプ構文でクエリの可読性がUP
2. 【要注意】CLI/APIのデフォルトがGoogleSQLに変更
3. SQLでIAMタグを直接管理
4. データ品質スキャンの結果をカタログで一元管理
5. クエリのオプションジョブ作成モード
6. SQL翻訳のパフォーマンスをYAMLで最適化
7. 別リージョンのSpannerに直接クエリ
8. Cloud StorageからBigQueryへのイベントドリブン転送
9. 画面遷移不要!クエリを書きながらスキーマを確認
10. リソース使用率チャートの登場
SQL開発の生産性が劇的に向上
日々のデータ分析業務で欠かせないSQLクエリ。2025年度上半期には、このSQLの記述をより直感的で、読みやすく、メンテナンスしやすくするための機能が一般公開となりました。
アップデート① パイプ構文でクエリの可読性がUP
処理の順番通りに上から下へクエリを記述できる、パイプ構文という記述方法がリリースされました。データがどのように変換されていくのかが一目瞭然となり、チームでの開発や後からの見直しが格段に楽になります。
パイプ構文は、例えば以下に示すようなクエリ構造となり、データ処理の順番と同じようにクエリの記述・読み解きができます。
FROM `bigquery-public-data.usa_names.usa_1910_current`
|> WHERE gender = 'F'
|> AGGREGATE SUM(number) AS total_number
GROUP BY name
|> ORDER BY name
これを通常のGoogleSQLで記述すると以下のようになります。
SELECT
name,
SUM(number) AS total_number
FROM
`bigquery-public-data.usa_names.usa_1910_current`
WHERE
gender = 'F'
GROUP BY name
ORDER BY name;
パイプ構文は、記述や読み解きは直感的に行える一方で、多くの情報が存在しているのは通常の記述方法なので、あくまで一つの手段として覚えておくと良いでしょう。
アップデート② 【要注意】CLI/APIのデフォルトがGoogleSQLに変更
2025年8月1日より、コマンドラインツール(CLI)やAPIで実行するクエリの標準SQLがGoogleSQLになりました。これまでLegacySQLを前提としていた自動化スクリプトなどは、エラーになる可能性があるため注意が必要です。
データガバナンスと管理機能の強化
企業がデータを資産として活用する上で、そのデータを適切に管理・統制するデータガバナンスは不可欠です。BigQueryでは、データの発見から分類、品質管理に至るまで、ガバナンスを強化する機能が続々と一般公開となりました。
アップデート③ SQLでIAMタグを直接管理
ALTER SCHEMA文などを使って、データセットに管理用のタグをSQLで直接付与できます。これにより、タグに基づいたアクセス制御の自動化や、大規模なデータ分類の一元管理が容易になります。
例えば新規テーブルを作成するDDLにおいて、OPTIONSで以下のように記載することで、テーブルに対してタグを設定することができます。
タグの設定はKey-Valueペア(キーと値の組み合わせ)で行います。
CREATE TABLE PROJECT_ID.DATASET_ID.TABLE_ID (
id INT64
)
OPTIONS (
tags = [('department', 'marketing'), ('report_type', 'daily')]
);
アップデート④ データ品質スキャンの結果をカタログで一元管理
BigQueryテーブルのデータ品質で監視・維持するための機能です。
「特定の列はNULLであってはならない」「値はユニークであるべき」といった品質ルールを定義するだけで、Dataplexが定期的にテーブルをスキャンし、ルール違反を自動で検知します。品質ルールを満たさないデータが発見された場合はアラートが記録され、メール通知の設定も可能です。
パフォーマンスと効率性の追求
BigQueryの魅力は膨大なデータを扱えることだけではありません。クエリの実行速度やデータ転送といった作業の効率化も進化しています。
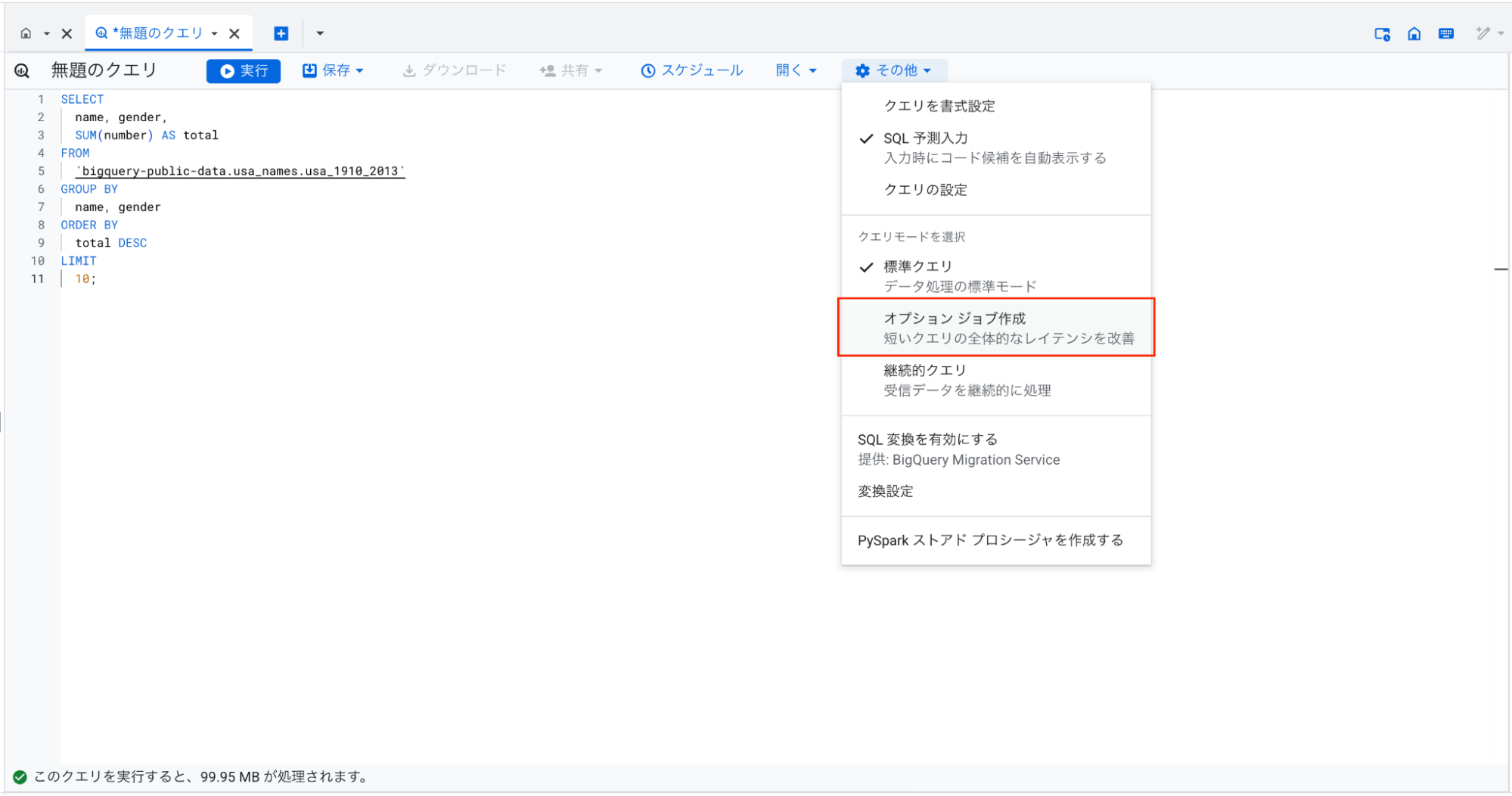
アップデート⑤ クエリのオプションジョブ作成モード
Looker StudioなどのBIツールから実行されるような、処理量の小さいクエリを高速化するモードです。
クエリエディタの「その他」メニューからクエリモードを選択できます。
ただし、Looker StudioやTableauのBigQuery標準コネクタ(カスタムクエリ)では標準クエリで実行されてしまうので、実際にBI高速化に活用するためには別途設定の検討が必要です。
BIツールがJDBCまたはODBCドライバの詳細な接続設定をカスタマイズできる場合、このモードを有効にできる可能性があります。この実装方法については検証が必要なので、また別の機会に紹介しようと思います。
アップデート⑥ SQL翻訳のパフォーマンスをYAMLで最適化
他DWHからの移行でバッチSQL翻訳機能を使う際に、YAML設定ファイルで変換ルールを定義できるようになりました。これにより、ターゲットとなるBigQueryの設計に合わせた、よりパフォーマンスの高いSQLへの変換が可能です。
外部連携とデータ活用の拡大
BigQueryは単体で完結するサービスではなく、他のサービスと連携することで真価を発揮します。データソースとの接続からコンソールでの使いやすさまで、データ活用をさらにスムーズにするアップデートを紹介します。
アップデート⑦ 別リージョンのSpannerに直接クエリ
BigQueryとCloud Spannerが異なるリージョンにある場合でも、BigQueryからクエリを実行できます。
例えば、海外リージョンのCloud Spannerに保管されているデータに対して、日本国内リージョンのBigQueryプロジェクトからデータをクエリすることができます。これにより、グローバルに分散したデータを移動させることなく、横断的な分析が実現します。
ただし、クエリ実行時にはSpannerからのデータ転送料金が追加発生する点に注意が必要です。
アップデート⑧ Cloud StorageからBigQueryへのイベントドリブン転送
Cloud Storageへのファイル配置をトリガーに、データを自動転送できるようになりました。従来はCloud Run Functions等を利用し、Cloud Strageへのファイル配置を検知してデータ転送するプログラムを実装する方法が主流でしたが、BigQueryの標準機能で対応できるようになりました。
BigQuery Data Transfer Service(データ転送)の「転送を作成」で、スケジュールオプションを「イベントドリブン」を選択して利用します。
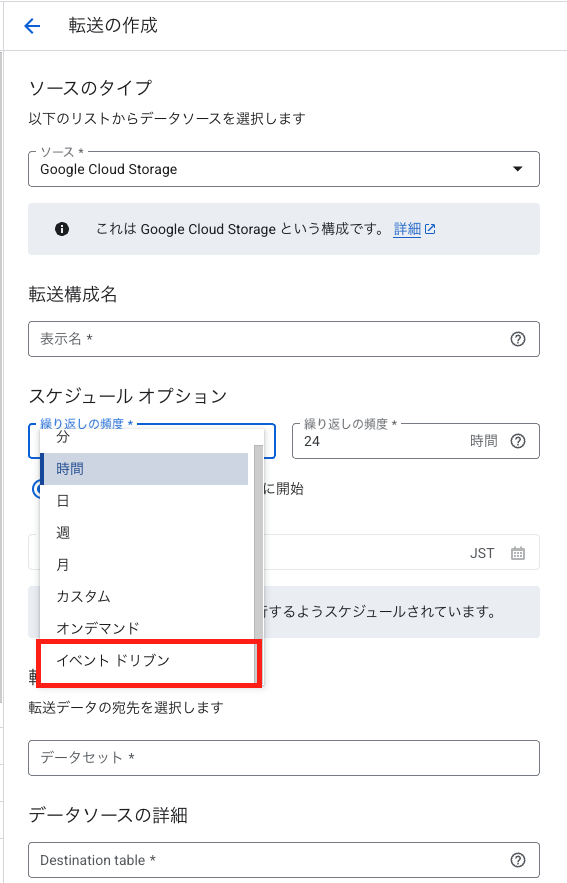
なお、こちらのイベントドリブン転送を利用するには、Pub/Sub APIを有効化して各種権限設定等を行う必要があるので、詳しくはGoogle Cloud 公式リファレンスを参考に設定してください。
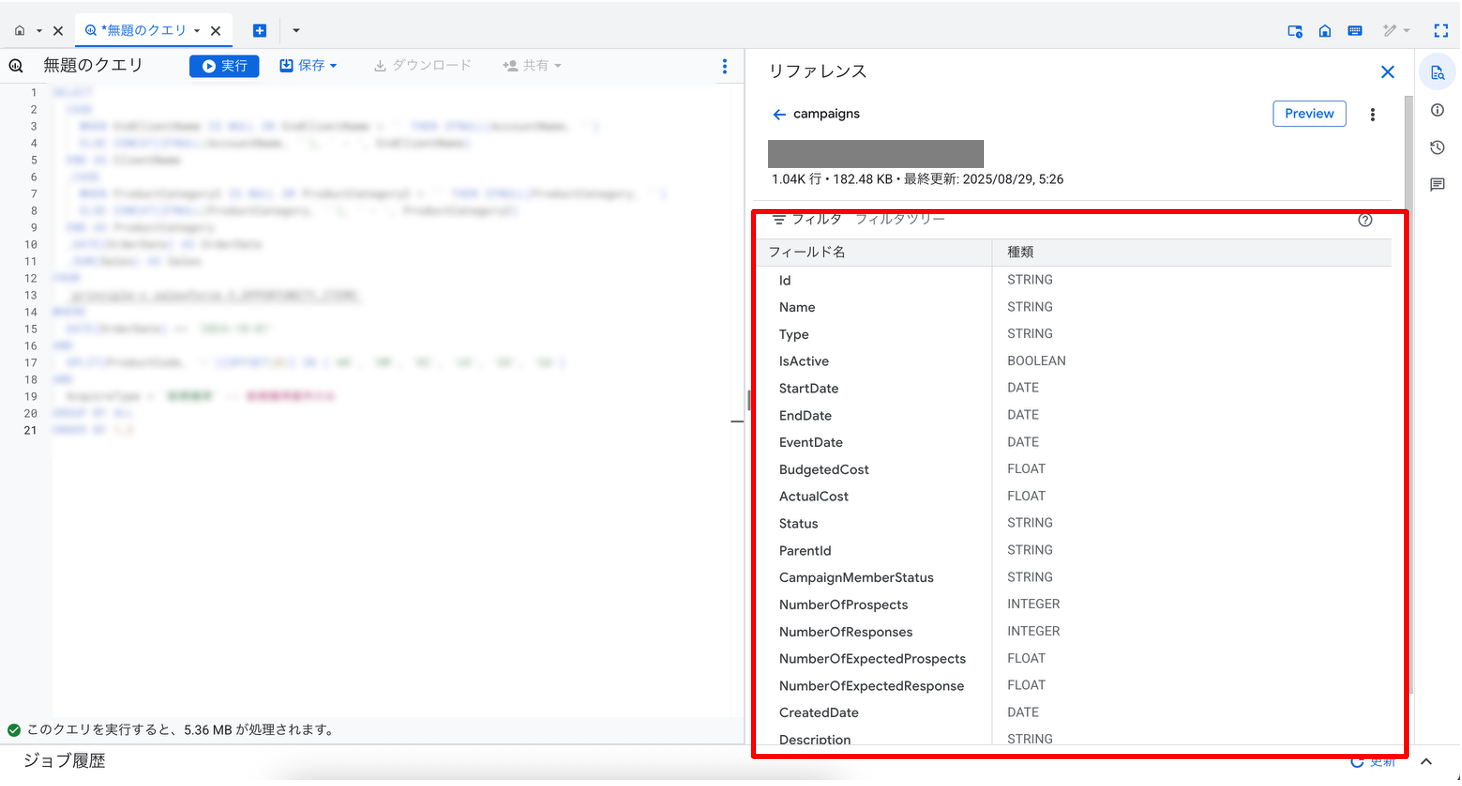
アップデート⑨ 画面遷移不要!クエリを書きながらスキーマを確認
クエリ作成中にテーブルのスキーマを確認できる「リファレンスパネル」が追加されました。コンソールのクエリ開発画面右側のメニューから「リファレンス」をクリックすると、クエリ内で参照しているデータセットの情報が表示されます。
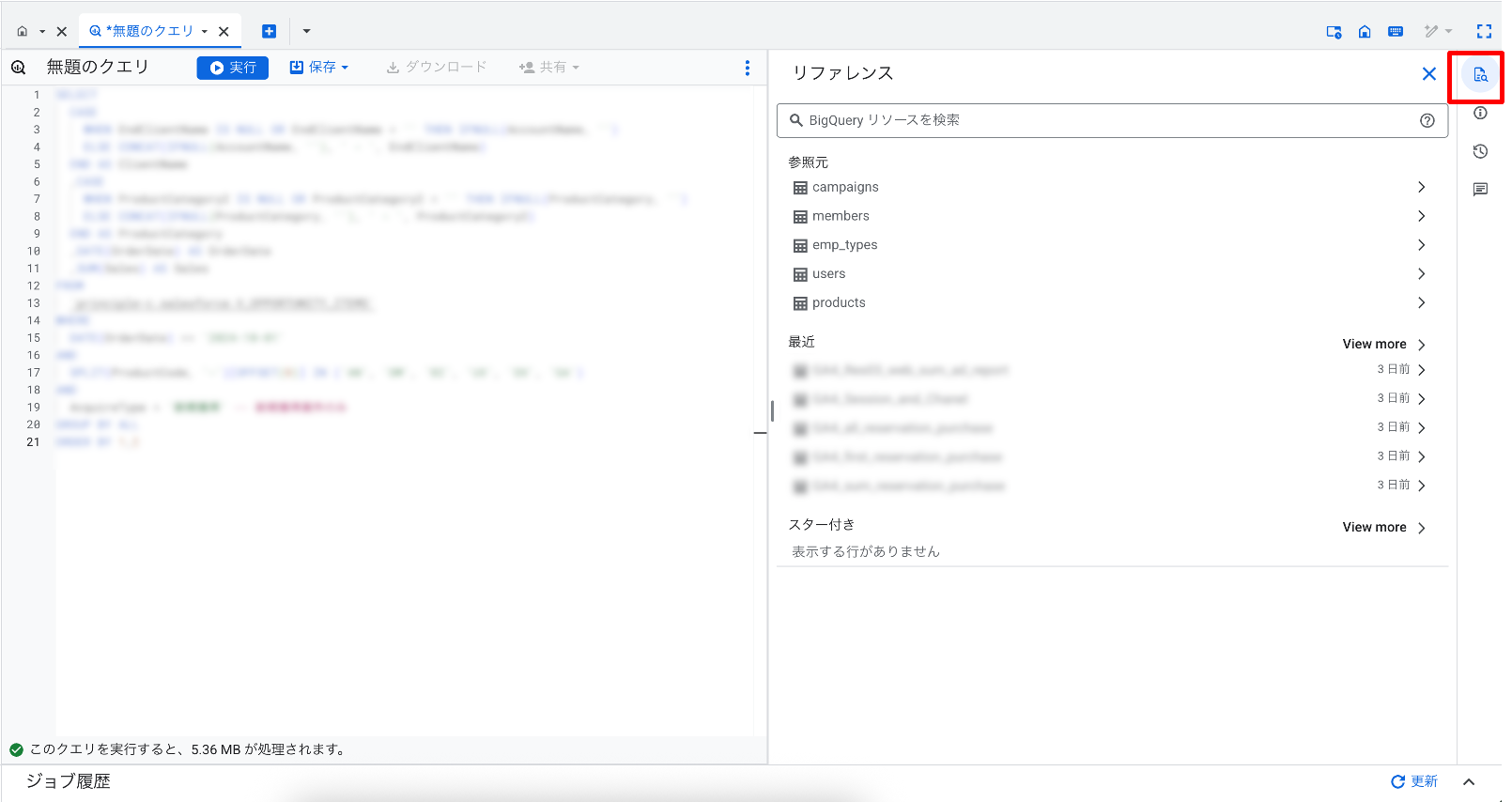
テーブルをクリックすると、フィールド名やデータ型などの情報が表示され、画面を移動することなくテーブルのスキーマを確認することができます。
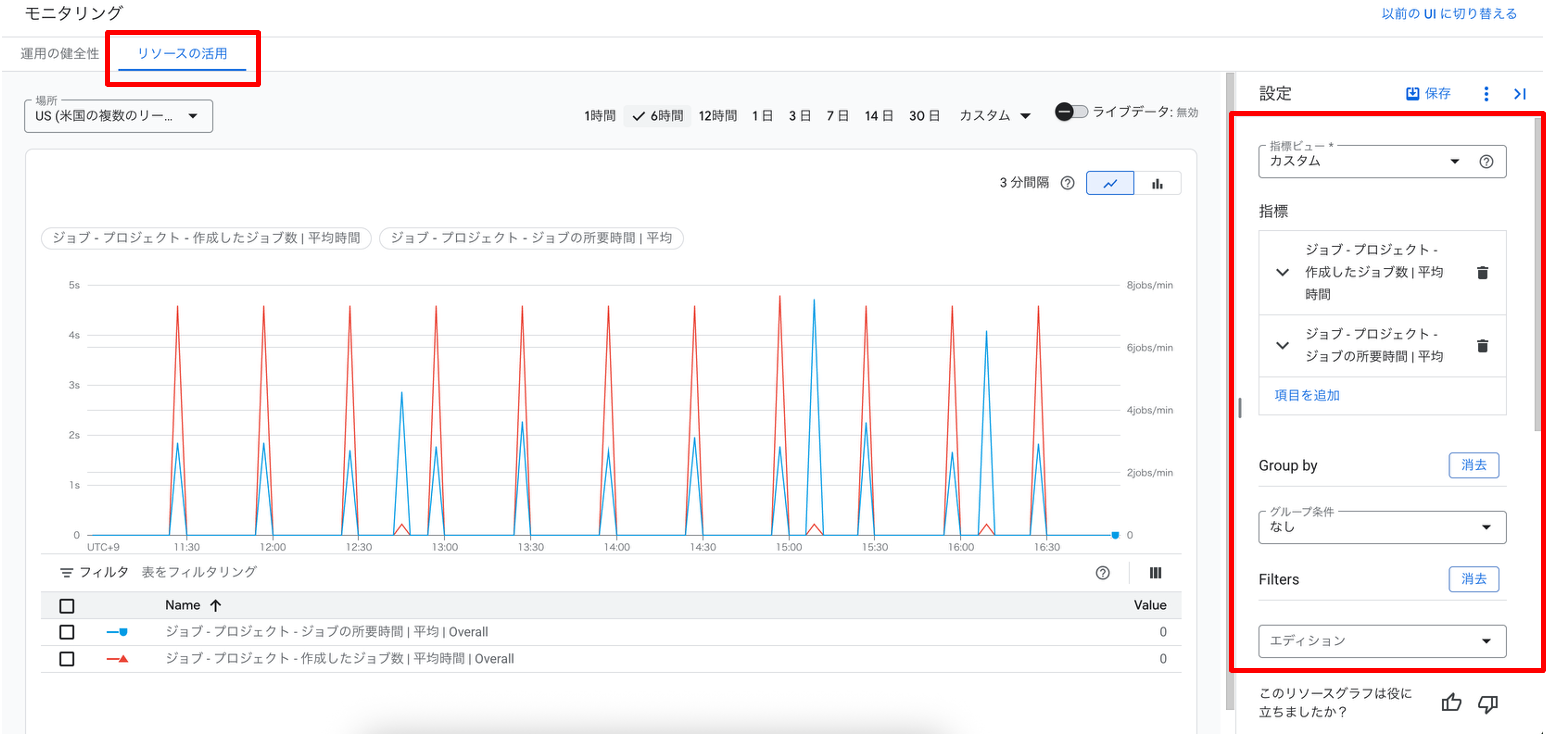
アップデート⑩ リソース使用率チャートの登場
「リソース使用率チャート」が一般公開され、過去のリソース使用量をトラッキングし、将来のリソース計画やパフォーマンスのトラブルシューティングができるようになりました。
確認するには、Google CloudコンソールからBigQueryの「モニタリング」へ移動し、「リソースの活用」タブへ移動します。
画面右側の設定画面から、自分が確認したい指標を選択したり、集計方法やフィルタを設定したりすることで、詳細なリソース使用状況を確認することができます。
最後に
この記事では、2025年度上半期に一般公開となったBigQueryの主要なアップデート10選を紹介しました。
これらのアップデートから、BigQueryが単なる高速な分析エンジンとしてだけでなく、開発者体験の向上、エンタープライズレベルのガバナンス、運用効率を重視した総合的なデータプラットフォームへと進化を続けていることがわかります。
弊社ではBigQueryを中心としたデータ基盤構築や、最新機能を活用した分析支援を行っております。Google Cloudの活用でお困りのことがあれば、お気軽にお問い合わせください。