
Tableauを活用する際に、散布図はよく扱われるグラフの一つです。本記事ではTableauで散布図を作成する方法と応用的なクラスタリングの実装方法を2回に分けて解説しています。
前回記事「今の散布図で大丈夫?Tableauでの効果的な散布図の使い方(その1)」では、パラメータを用いた動的なグラフを作成しました。今回は発展編としてクラスタリングを使ってより高度な分析をしてみましょう。
クラスタリングとは
まずはWikipediaの内容を確認してみましょう。
定義
クラスタリング (英:
clustering)、クラスタ解析(クラスタかいせき)、クラスター分析(クラスターぶんせき)は、データ解析手法(特に多変量解析手法)の一種。教師なしデータ分類手法、つまり与えられたデータを外的基準なしに自動的に分類する手法。また、そのアルゴリズム。さまざまな手法が提案されているが、大きく分けるとデータの分類が階層的になされる階層型手法と、特定のクラスタ数に分類する非階層的手法とがある。それぞれの代表的な手法としてウォード法、K平均法などがある。
wikipedia – データ・クラスタリング より(2022/05/24時点)
要するにクラスタリングとは「データの散らばり具合に応じてクラスターを作成する手法」の事です(クラスター = グループ)。 人間では気付かないような基準でデータをグループに分ける事ができます。
k-means法
Tableauにおけるクラスタリングは「k-means(K平均法)」によって実装されています。これは大量のデータに対して早くクラスタリングを実行したい時に取り入れられるシンプルな手法です。
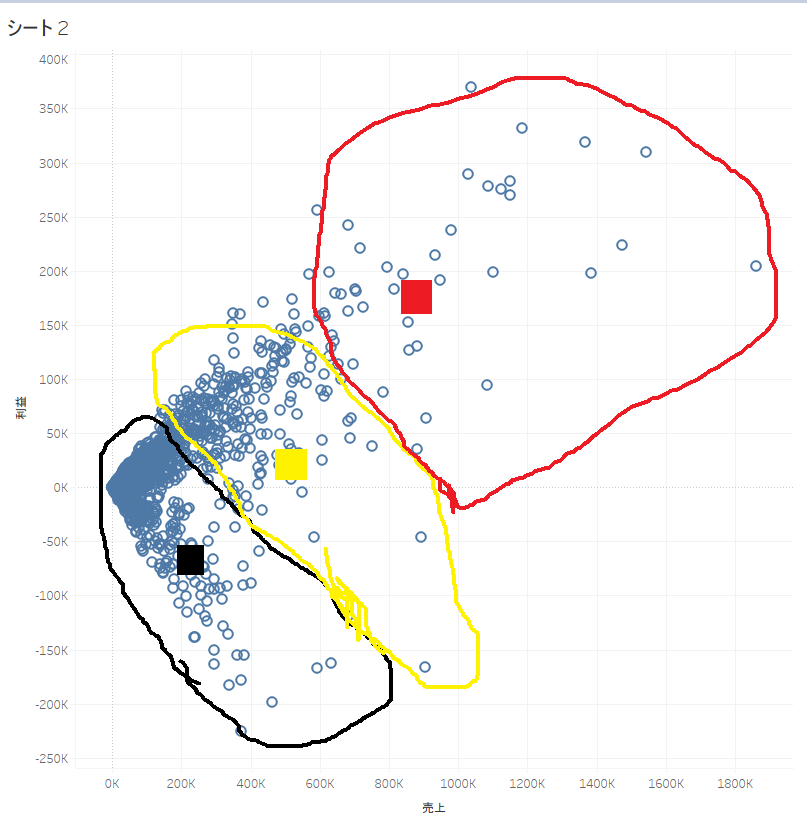
例として、売上 × 利益を年月(オーダー日)、 都道府県別にプロットした散布図を考えてみましょう。
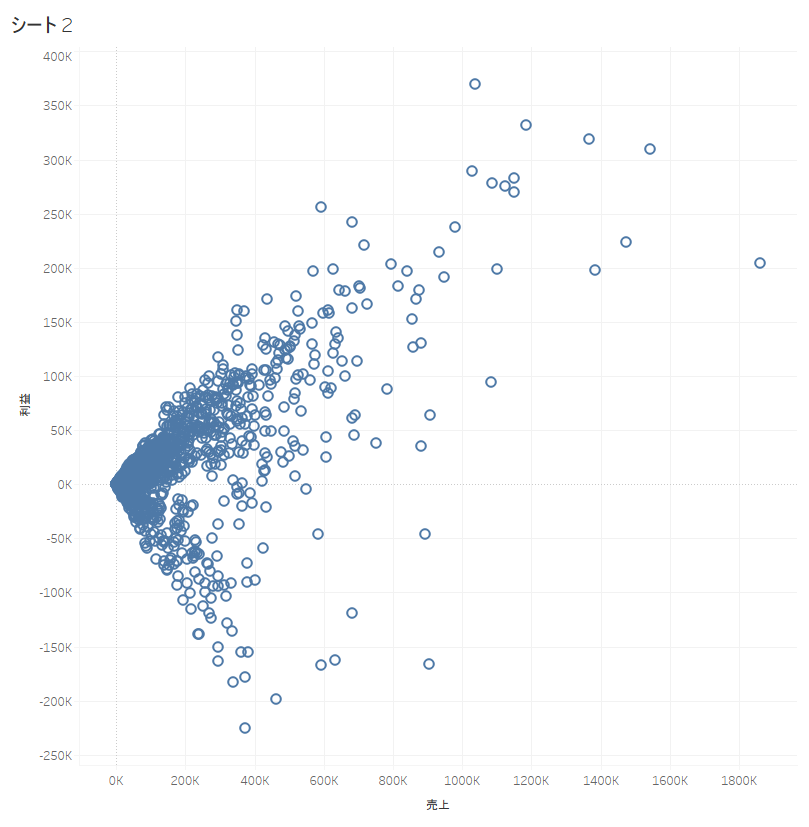
「く」の字の様な散布図ですね。
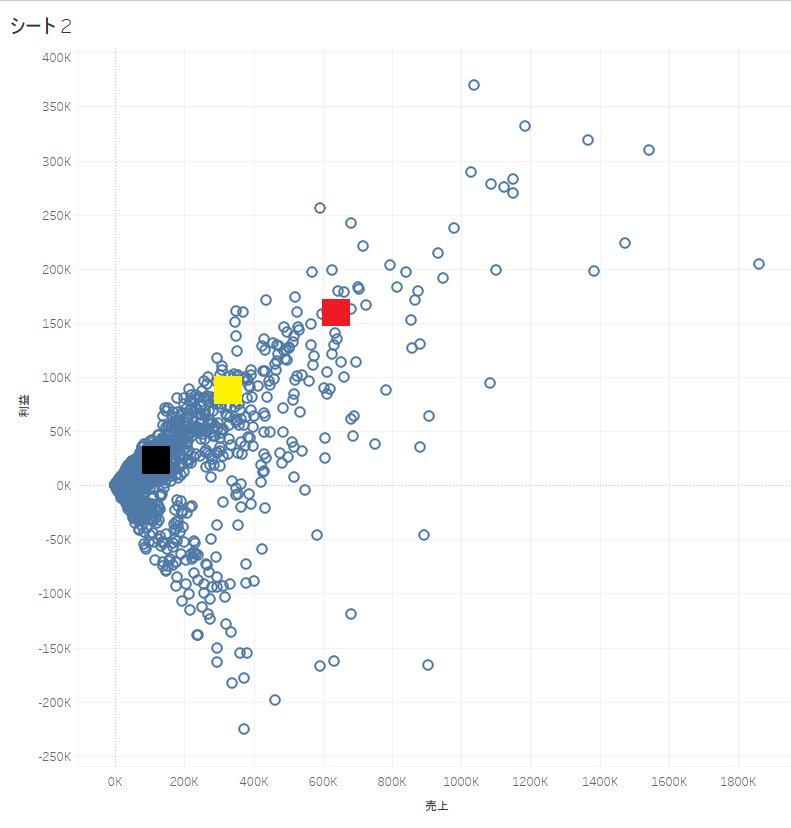
Tableauでは指定した数のクラスタの重心が初期値として割り振られます。
次に各プロットは、クラスタの重心との距離が最も近いクラスタへ割り振られます。
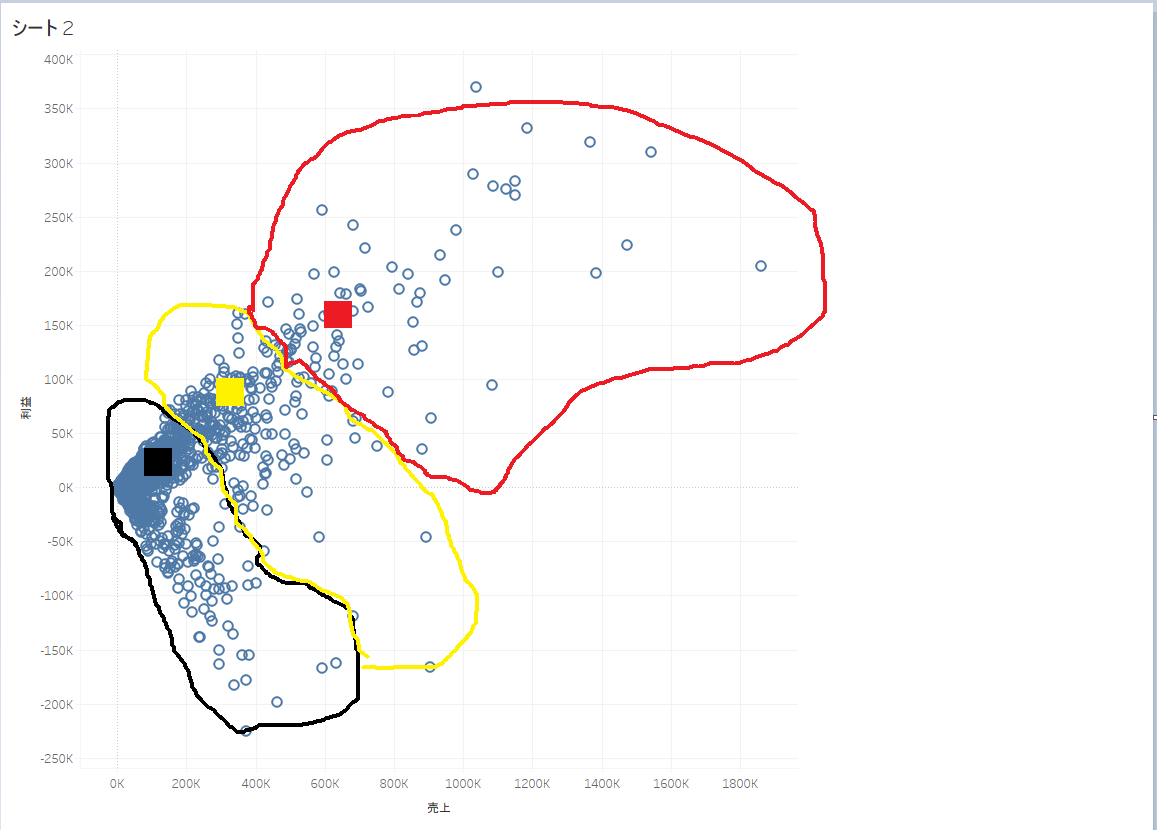
作成できたクラスタで新たに重心を算出(元のクラスタの重心から移動します)。
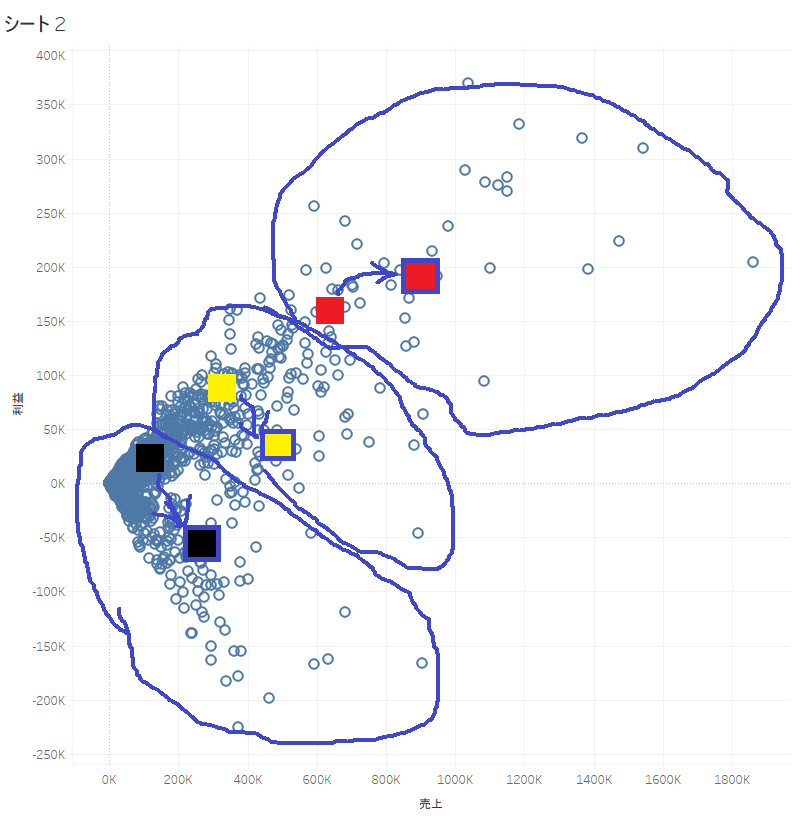
各プロットは最も近いクラスタの重心が属するクラスタに割り当てられる。
そしてもう一度、新しいクラスタの重心を算出….と、クラスタの重心が収束するまで繰り返します。
これによりクラスタリングが実現します。
K-means法のフロー
① クラスターの重心となる初期値を設定
② 最も近いクラスタの重心を持つクラスタに割り振る
③ 新しくできたクラスタの重心を算出
④ クラスタの重心が収束するまで②〜③を繰り返す。
クラスタリングの使用シミュレーション
ここからはTableau公式ドキュメント「データ内のクラスターを見つける – Tableau」を参考に、クラスタリングの使用例を見ていきましょう。
目的は都道府県別の課題を調べること
あなたは今スーパーマーケットの経営企画部の一員です。市町村別の課題を確認していきたいという目的を持っているとしましょう。
分析に使えそうな変数を選択する
クラスタリングは計算によって人間が気付かない様なグループ分けをしてくれる便利な技術ですが、生み出されたグループに解釈を付け加えるのはあなたの役目です。解釈に役立ちそうな変数を選択しましょう。
今回は以下の変数を設定しました。
| 変数 | 理由 |
| 売上 | 売上が無いと利益が上がらない為、課題の要因となりうるから。 |
| 利益 | 利益は一般的に重要な指標の一つであり、今回の課題とするか否かを、利益の大きさで判断するケースが多いから。 |
| 数量 | 売れている数量は地方ごとに特徴があるから課題を見つけるのに良い指標と考えたから。 |
Tableauでクラスタリングを実行する
散布図は二次元なので、上記の変数から選んだ[売上][利益]を表示させることにしました。※結果が意味のないものであれば表示する変数を色々組み合わせて試します。
以下は実行の手順です。
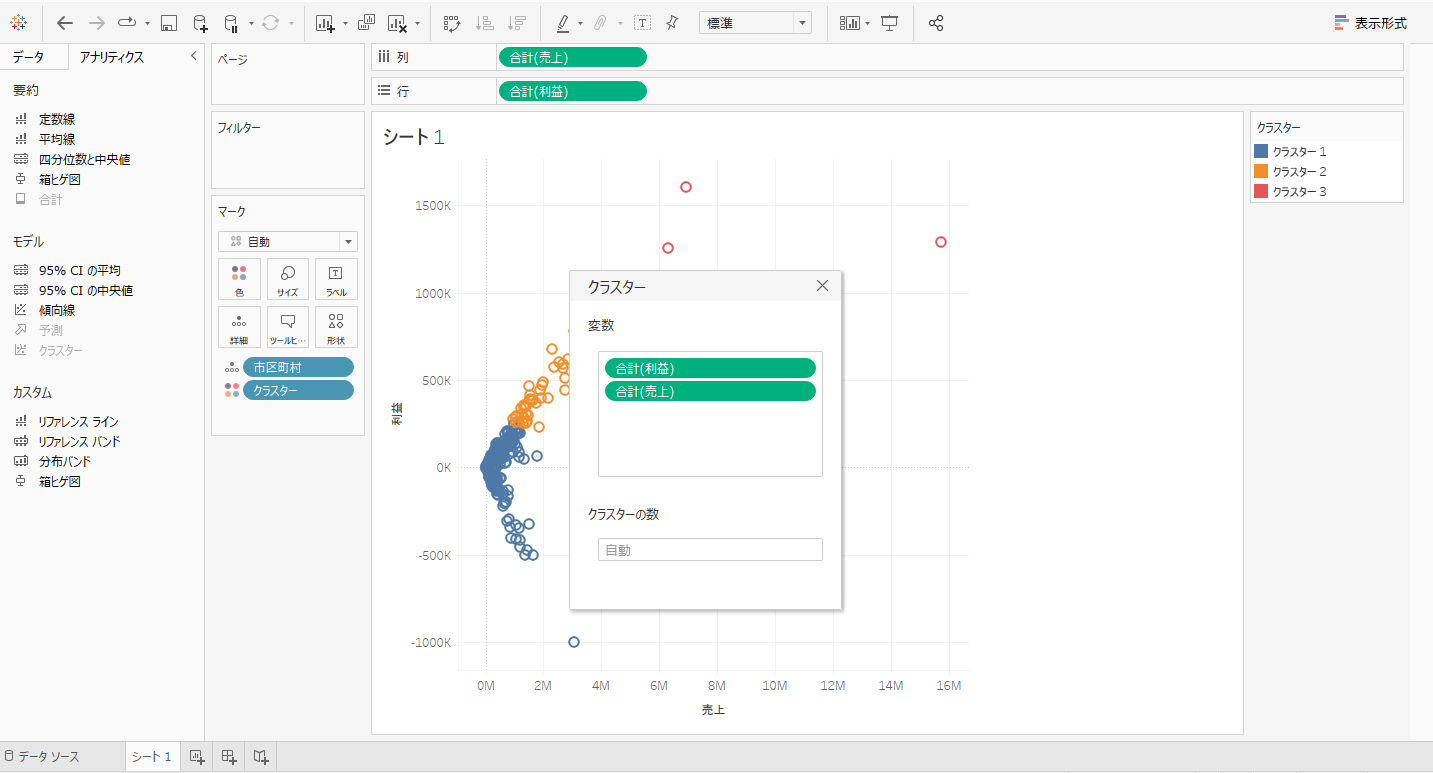
手順① 行に「利益」、列に「売上」、詳細に「市町村」を持つグラフを作成します。
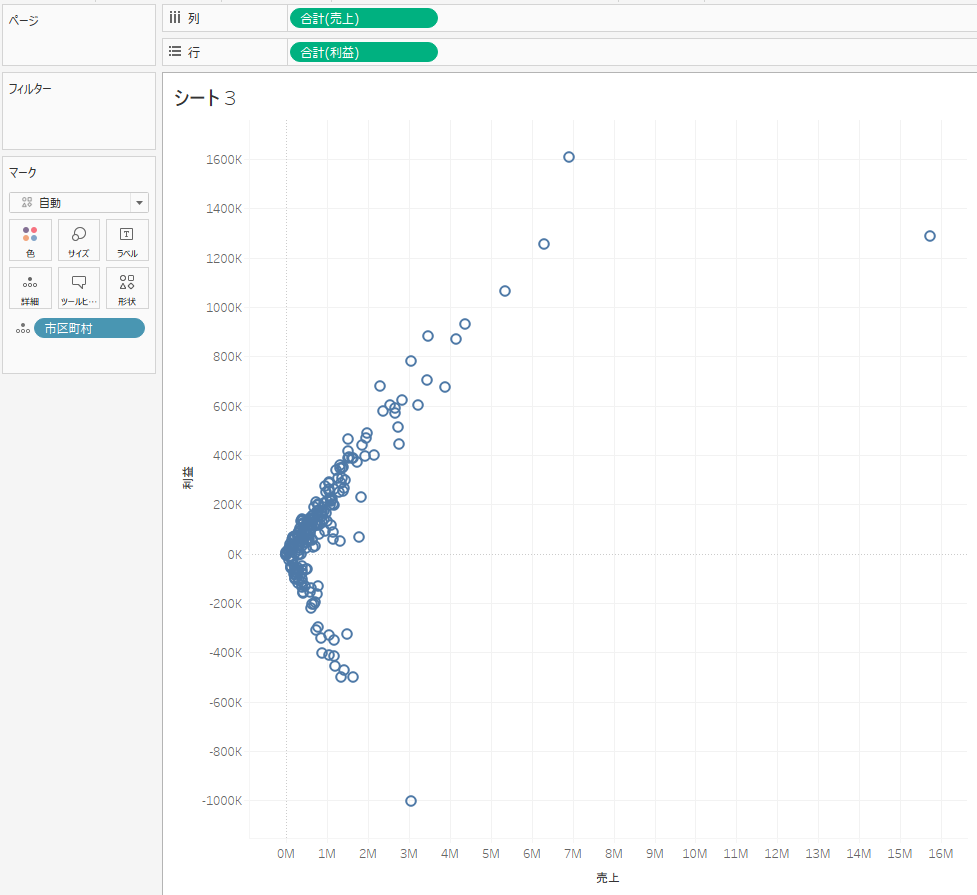
手順② 画面左側のサイドバーのアナリティクスペインから「クラスター」をクリックしたまま、シートにドラッグすると、クラスタの表示がされるのでそこにドロップ。
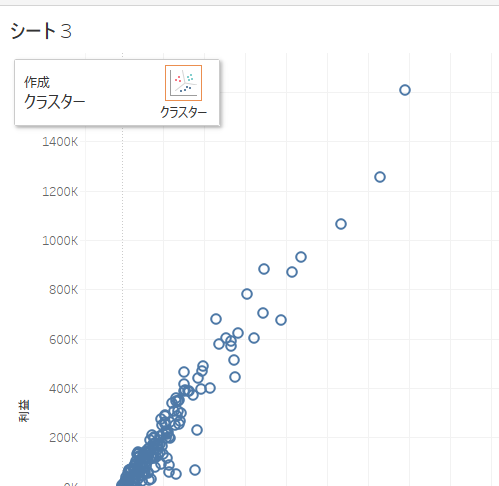
手順③ 「クラスター」というウィンドウが表示されます。このウィンドウでクラスタの変数やクラスターの数を設定することができます。クラスターの変数に「数量」を追加してください。
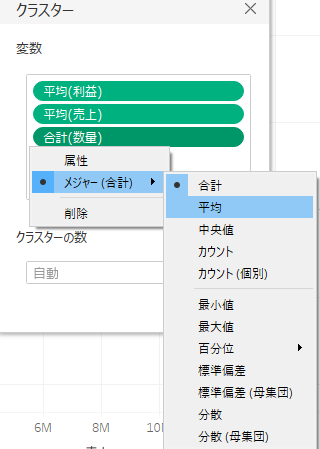
手順④ クラスターの変数の集計方法を変更。
デフォルトでは各市町村ごとの各指標は合計されています。このままだとクラスタのプロットは消費者人口の多さがクラスタリングに影響します。
今回は市町村ごとの一回分の取引を比較したい為、消費者人数の影響を排除してクラスタリングをできるように、[利益,売上,数量]を各市町村の平均値でプロットする事にしました(OrderID別の平均値になります)。
設定は変数にカーソルを合わせると表示される「▼」マークから設定できます。
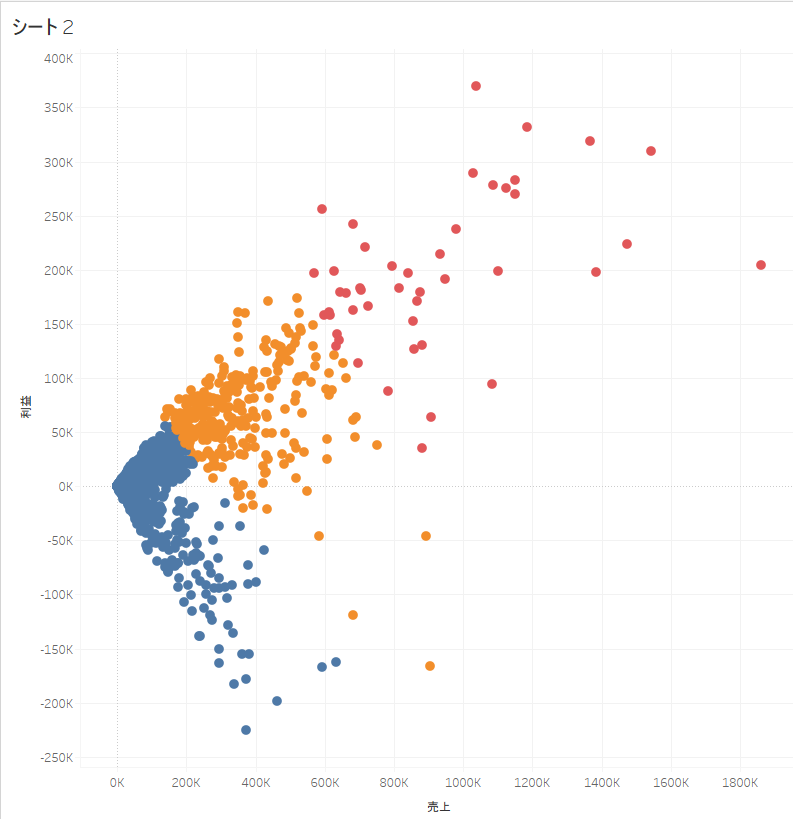
また、クラスタの数は最大50個まで指定することができるのですが、デフォルトだと最適なクラスタの数を自動で算出してくれるロジックが適用されるので、今回はそのまま従う事にします。結果的にクラスタの数は3つとなりましたね。
結果を観察する
散布図の行列(売上と利益)の集計方法を合計から平均に変換して、クラスタリングの結果を観察してみましょう。
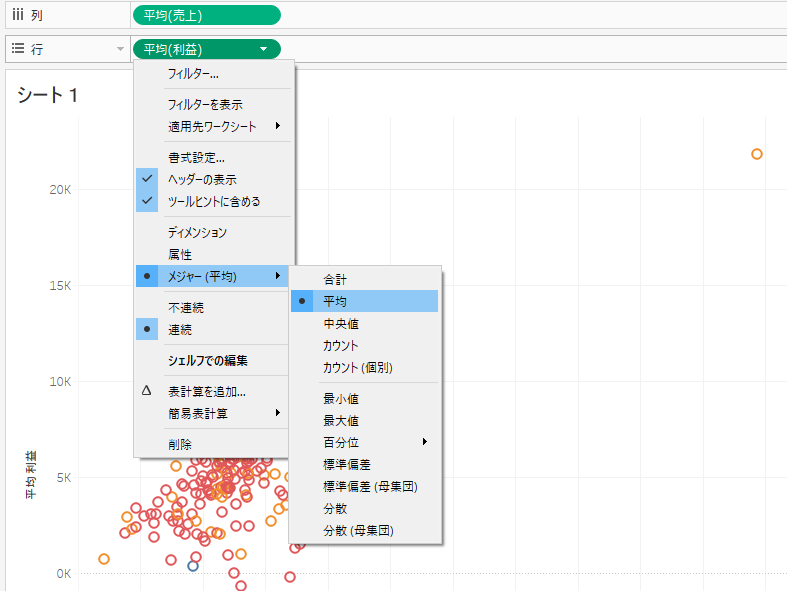
クラスタリングで用いた変数は「売上・利益の平均値」ですので、散布図の軸も同様の値に変更しましょう。列と行の売上と利益のピルの▼から平均値に変更してください。
クラスターの詳細を確認する
マークカードに追加された「クラスター」を右クリックし、「クラスターの説明」を選択すると、クラスタリングの詳細が表示されます。
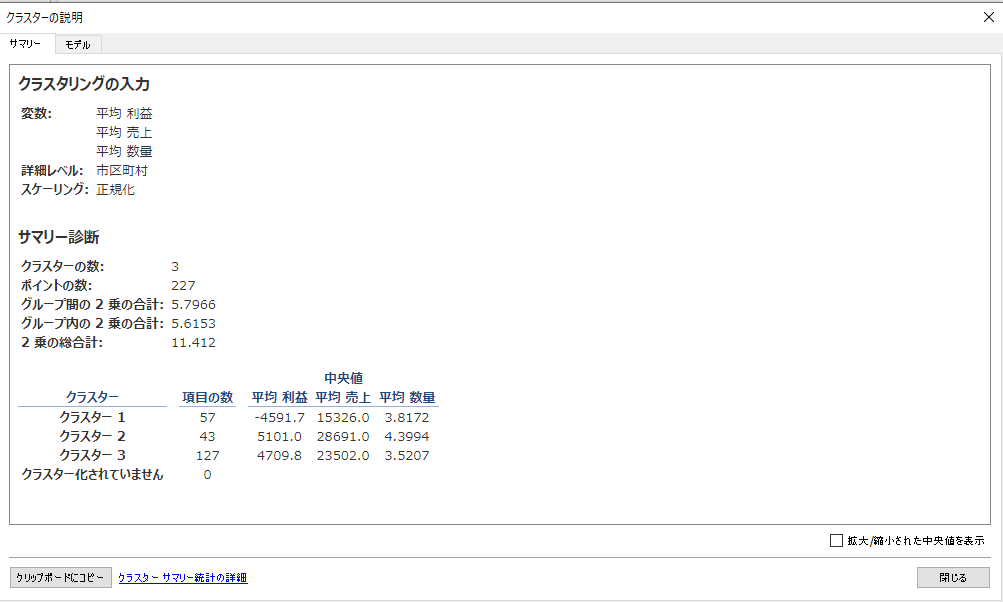
「クラスタの説明」からクラスタごとの特徴を分析する
「クラスターの説明」には気になる情報がたくさんあるかと思いますが、これらはクラスターの散らばり具合やクラスタ間の距離、統計的なモデル評価指数を表示しており、高度な分析をするためのものです。詳しくは公式のページ「データ内のクラスターを見つける – Tableau」をご覧ください。
今回はこの部分を観察してみましょう。
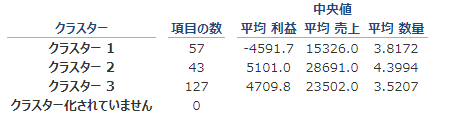
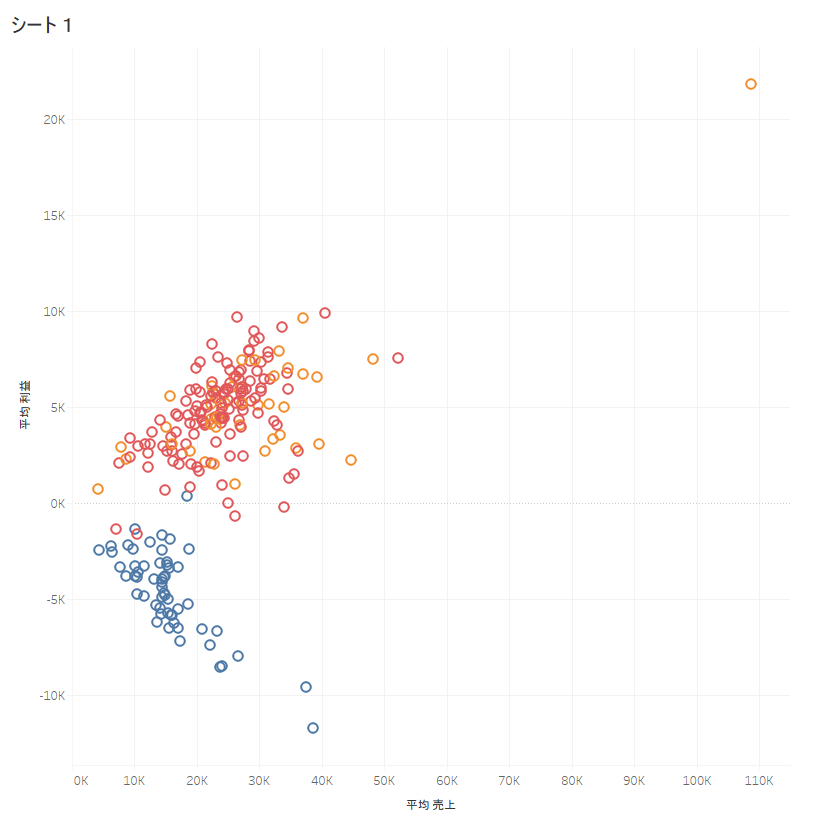
クラスター内の平均値がそれぞれ表示されています。
これらの値を解釈し、グループ名をつけるとすると、以下のような形になるでしょうか。
| クラスタ名 | 特徴 | 命名 |
| クラスター1 | 利益と売上が最も低い | 低収益グループ |
| クラスター2 | 利益と売上が最も高い | 高収益グループ |
| クラスター3 | 利益と売上はクラスタ内で平均的 | 中間グループ |
この中で、低収益グループには課題がある可能性が高いです。
クラスターを改名する
クラスターの名称が決まったところで、Tableauで名前を早速変更しましょう。そのためにはクラスターをクラスタグループ型の項目に変更します。

方法は簡単です。作成したマークカード上のクラスターを「Ctrl」を押しながらデータペインにドラッグ&ドロップするだけです。
追加された項目を右クリックして「グループの編集」をクリック。
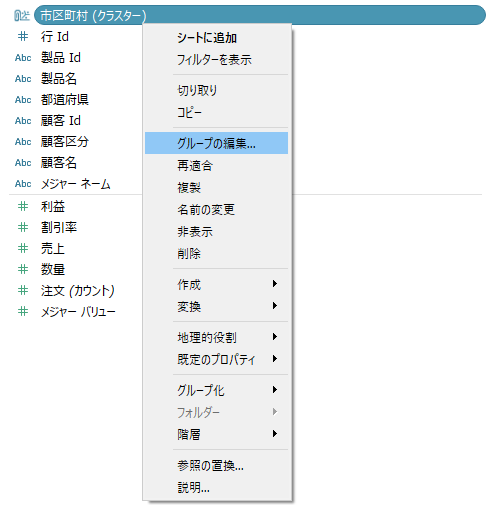
クラスターを選択して名称を変更していきましょう。クラスター上で右クリックをしてメニューの「名前を変更」から設定できます。
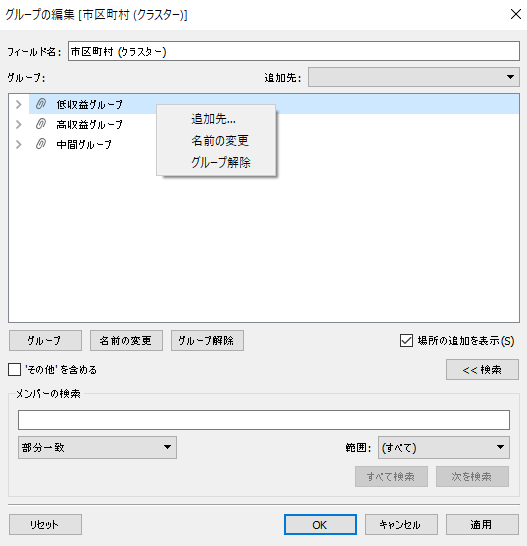
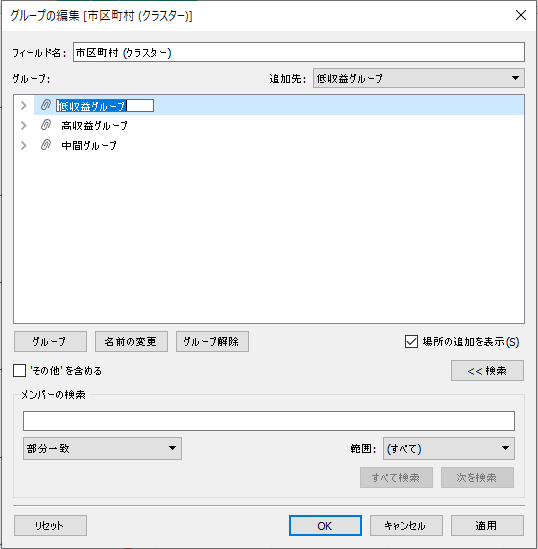
次のアクションを決める
クラスタリングされたデータに解釈を加えたあとアクションは、以下の2つに分かれます。
- クラスタの数や変数の種類を変更して、問題をもう一度探しなおす
- 作成したクラスタを用いてどんな問題があるか深堀してみる
今回は後者を選択し、問題を深堀りしてみます。
市町村別に分かれたデータを地図に表してみる
① 市区町村の項目のデータ型を文字型から「地理的値」型に変更
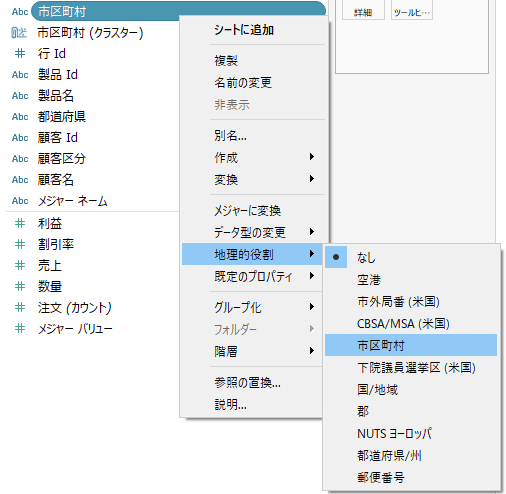
② 自動生成される経度と緯度を、列と行に追加
③ 市区町村をマークカードの「詳細」にプロット
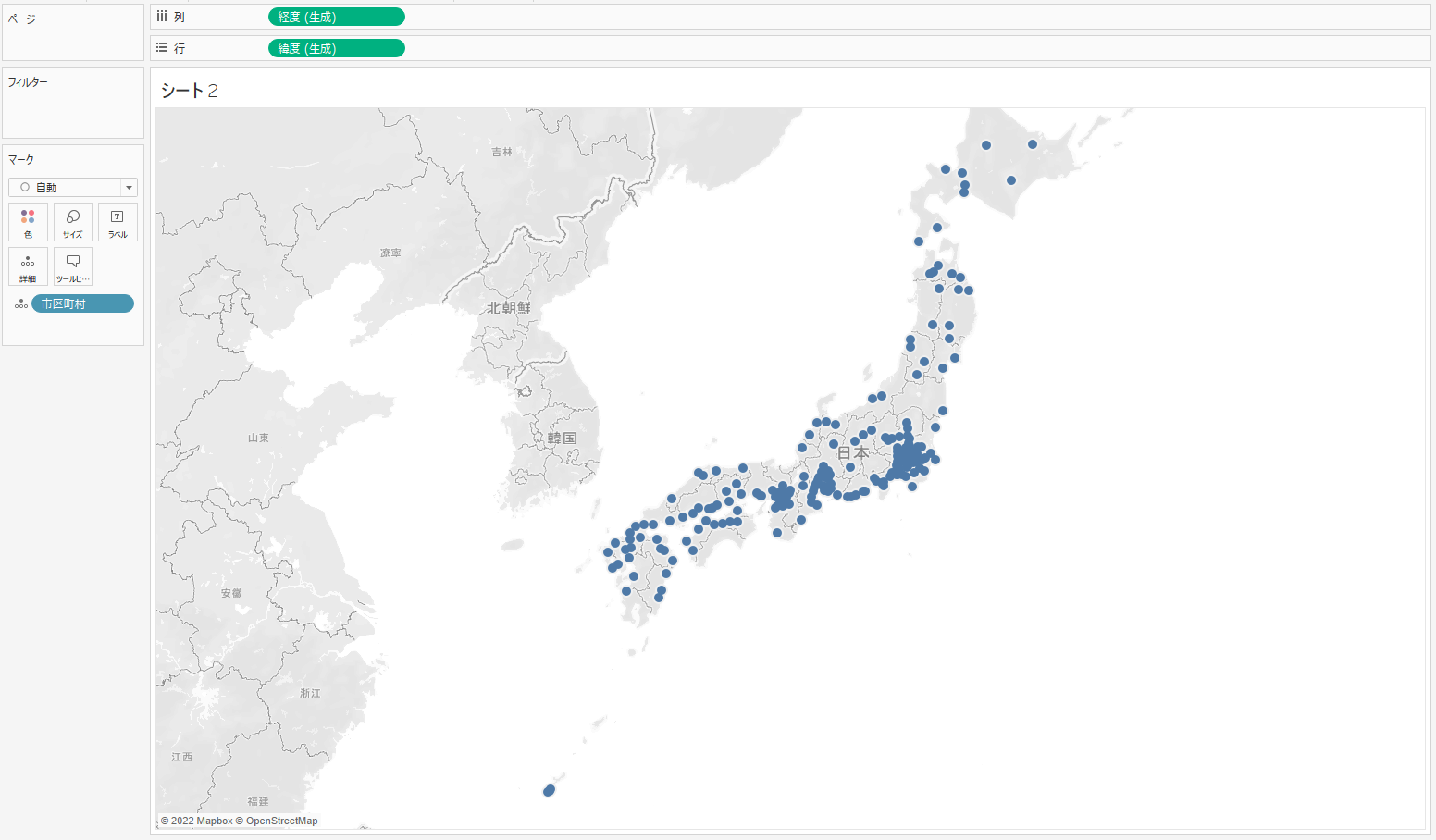
④ クラスタグループ型項目をマークカードの「色」に追加
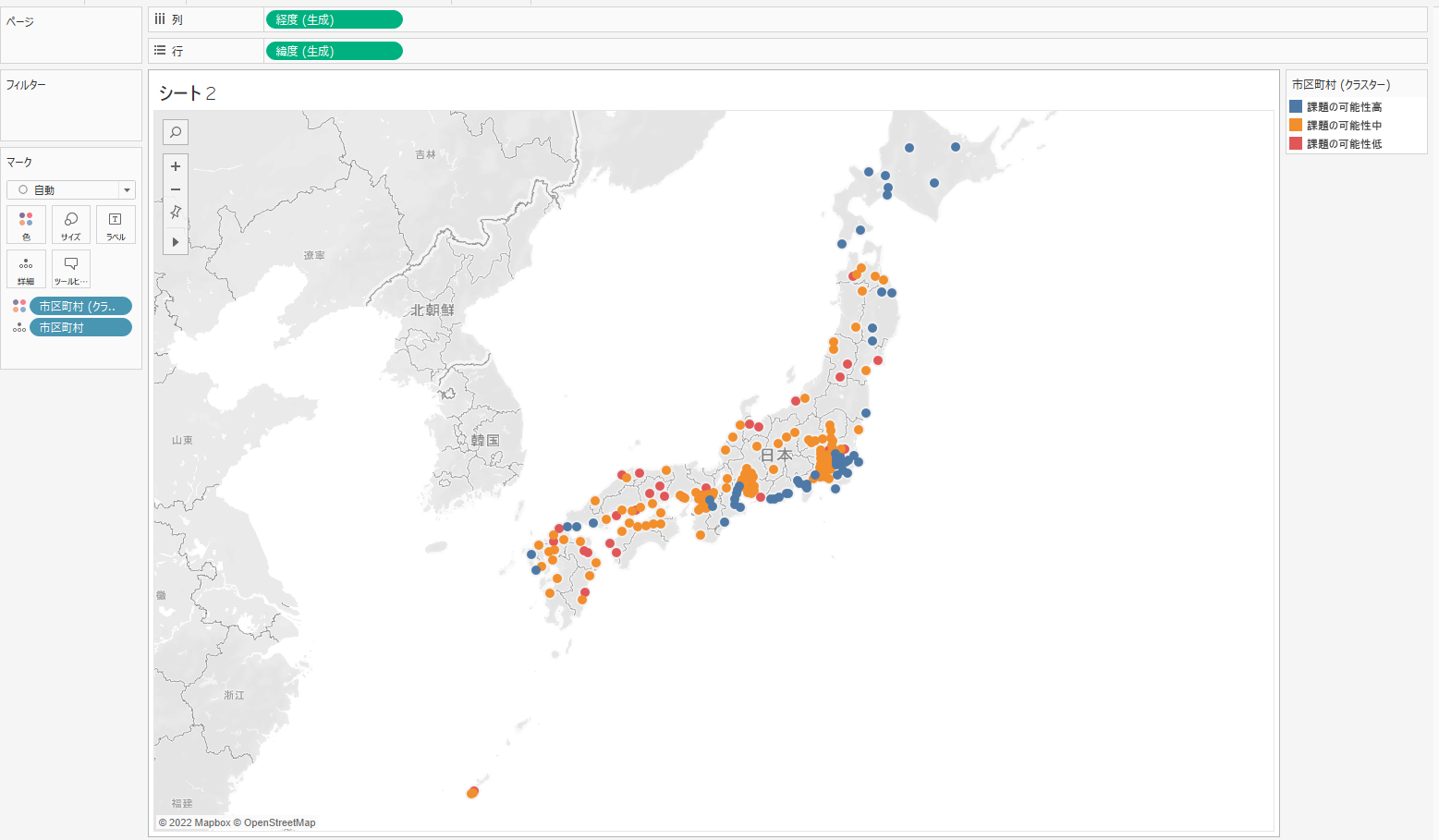
⑤ 「低収益グループ」クラスターをハイライト表示
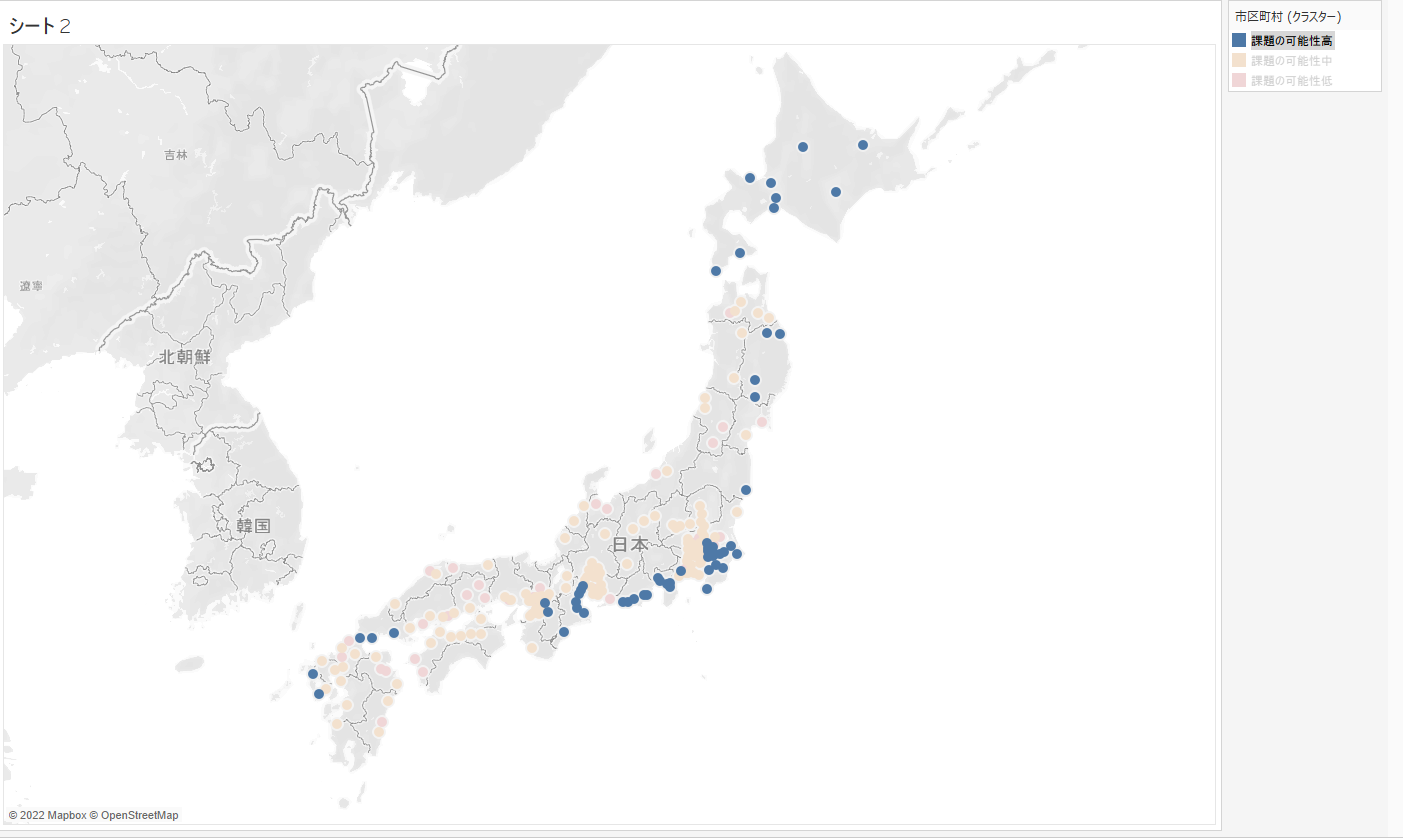
データの表示方法を地図に変更することによって、課題がある可能性が高い市区町村は千葉県に集中しているという事が読み取れました。このように、問題を追及していく一つの糸口として、クラスタリングを利用することができます。
まとめ
この記事では、Tableau上の散布図にクラスタリングを実装する方法を解説しました。人間では見つけられないようなクラスタを割り振る事ができるこの機能は、データに新たな切り口を見つける事に役立つでしょう。
本記事でご紹介したように、Tableauを利用することで、散布図に機能・価値を加えることができます。弊社ではお客様に合わせたダッシュボードの構築だけでなく、トレーニングのご依頼、デザイン等のご相談も承っておりますのでお気軽にお問い合わせください。







