BigQuery MLによる予測の全体像
機械学習を学ぶにあたり、その全体像が提示されていないことが妨げになっている気がしています。筆者も勉強中の身ではありますが、自分自身の学びの整理のためにも本記事を執筆しています。
本ブログ記事は、過度に詳細に踏み込まない代わりに、その全体像を提示することで、私と同様の学習者である多くのユーザーがBigQueryのMLエンジンを利用できるようになる(少なくともやってみようと思える)ことを目的としています。
全体像は以下の7ステップで説明できます。そのうち、純粋に機械学習周りの技術を使っているのは、3、4、5、6のステップであり、1、2は準備、7は検算です。
- データの取得と整形
- 整形の完了したデータのアップロード
- モデルの作成
- モデルの評価
- 特徴量の調整やモデルのオプションの調整
- 予測値の取り出し
- 検算
① データの取得と整形
機械学習にはある程度まとまった量のデータが必要です。本ブログの例で言えば、過去の中古マンションの取引のデータが必要です。また、取得したデータをそのまま全量、機械学習で使えることは稀です。
NULL値のレコードの除外や、表記のゆらぎの統一、コード化されて入力されている項目の読み解きなどがこのステップに入ります。
また、このブログを読み終わった読者の中には自分でもやってみたい。と思う方がいらっしゃるかもしれません。
データには機械学習向きのものと、そうでないものがあります。機械学習初心者の方は、まずは、このブログに書いてあることを再現するのが良いかと思います。
② 整形の完了したデータのアップロード
予測に使うデータをBigQueryの機械学習で利用するためには、予測の元となるデータをBigQueryにアップロードする必要があります。整形したデータをBigQueryにアップロードしましょう。BigQueryへのデータのアップロード方法はいくつかありますが、csvファイルをアップロードでき、それが一番わかりやすいので、お勧めです。
BigQueryにアップロードされたデータはテーブル(表のこと)として保存されます。
③ 「モデル」の作成
モデルというのは、大雑把に言ってしまうと、複数の入力(築年数や、面積、駅までの徒歩分数等・・・)から、一つの出力(予測取引額)を取り出すための計算式です。築年数や、駅からの徒歩分数などに重み付けをして、より正確に取引額の予測をできるように調整されます。この計算式が優れていれば優れているほど、予測精度が高まるということになります。
機械学習における入力は「特徴量」と呼ばれますので、覚えておくと、書籍等で学習する際に戸惑いが少なくなります。
④「モデル」の評価
モデルの作成は、(入力する特徴量の種類数にもよりますが)10行程度のSQL文で実行できますが、作っておしまいではありません。どの程度の精度で予測ができているかを確かめなければ、業務上で利用できるのか、どの程度信頼して良いのか分かりません。
そのために行うのが「モデル」の評価です。評価も、(入力する特徴量の種類数にもよりますが)10行程度のSQL文で実行できます。
⑤ 特徴量の調整やモデルのオプションの調整
このステップが楽しくも難しいところですが、モデルを評価したところ、精度がイマイチ。という場合に、精度を高めるための調整を行います。
調整方法(データ量を増やせない前提。データが増やせるなら、データを増やすのが最も有効な場合があります。)は、①インプットする特徴量を調整・増加する方向、②モデル作成時のオプションを調整する方向の2つの方向性があります。
こちらの書籍(Pythonで始める機械学習)には、特徴量の調整(特徴量エンジニアリングと言われます)の方法として、
- 指標を二乗したり、三乗した値を使う(多項式特徴量の利用)
- 指標同士を掛け算、割り算した値を使う(交互作用特徴量の利用)
- 連続的な指標をグループ化して、離散化する(ビニング)
などが紹介されています。
モデル作成時のオプションとしては、こちらのGoogle公式ヘルプに一覧があります。(が、私も全部は理解していません。一定レベルの性能を出すモデルが作れれば良いので、全部を理解する必要はないと思います。)
⑥ 予測値の取り出し
最後は予測値の取り出しです。この値を取り出すために機械学習の技術を利用したのですから、このステップが必要になるのは理解できると思います。
⑦ 検算
取得した予測値によっては、検算できる場合があります。たとえば、本ブログ記事で(学習用に)取り上げる中古マンションの取引額は、中古マンション販売ポータルサイトなどで販売額が掲載されていますので、機械学習のモデルが出力した予測値と実際の販売価格を比較することで、実際、どれくらい当てはまっているのかを検算できます。
機械学習が出した予測値だから・・・と無邪気に信じるのではなく、検算可能であれば検算する。という姿勢は重要なように思います。
それでは、一つ一つのステップの「実際のところ」を見てゆきましょう。
1. データの取得と整形
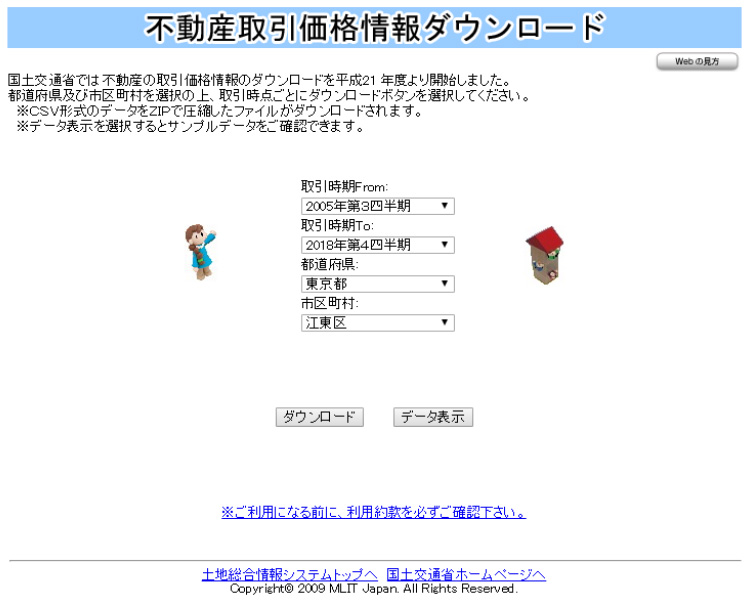
まず、中古マンションの取引価格のデータを国土交通省のこちらのサイトからダウンロードしました。期間は全期間、区は「江東区」を指定しました。(が、どの区でも良いと思います。)ファイルはcsvファイルとして取り出すことができます。
本当は「直近の取引のデータ」が大量に欲しいのですが、そうするとデータ量が少なくなってしまいますので、データが提供されている最も昔の期間から直近までを取得しました。おそらく誤差の要因となります。
csvファイルをTableau Prepに取り込んで整形します。
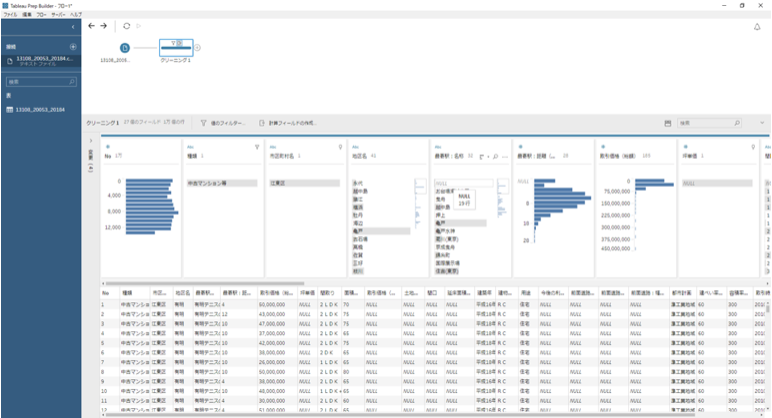
Tableau Prepは、NULLのデータがどのくらいあるのか、一つのディメンションに何種類のディメンションメンバーが存在し、それぞれが何レコード存在するのか?などをビジュアルに確認しながら、整形できるので非常に便利です。
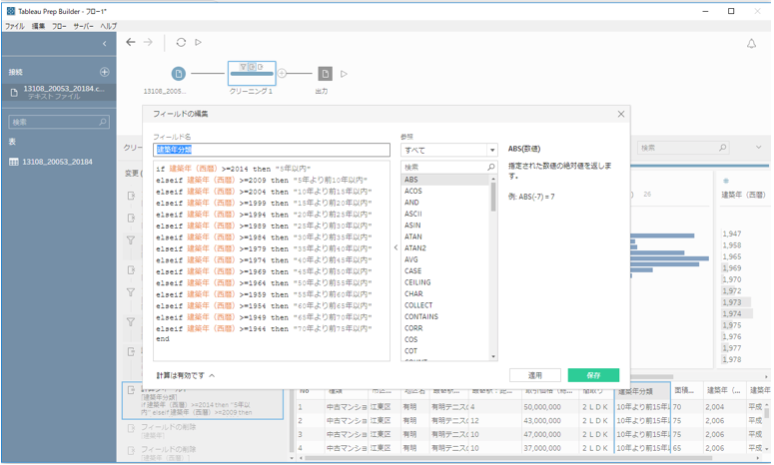
建築年が西暦で表現されていたのを、グループ化する作業も、Tableau Prepで行いました。データ量に対して、オリジナルのデータが分割されすぎていると感じたためです。特徴量の一つをビニング(ビン化)しているとも言えます。
2. 整形の完了したデータのアップロード
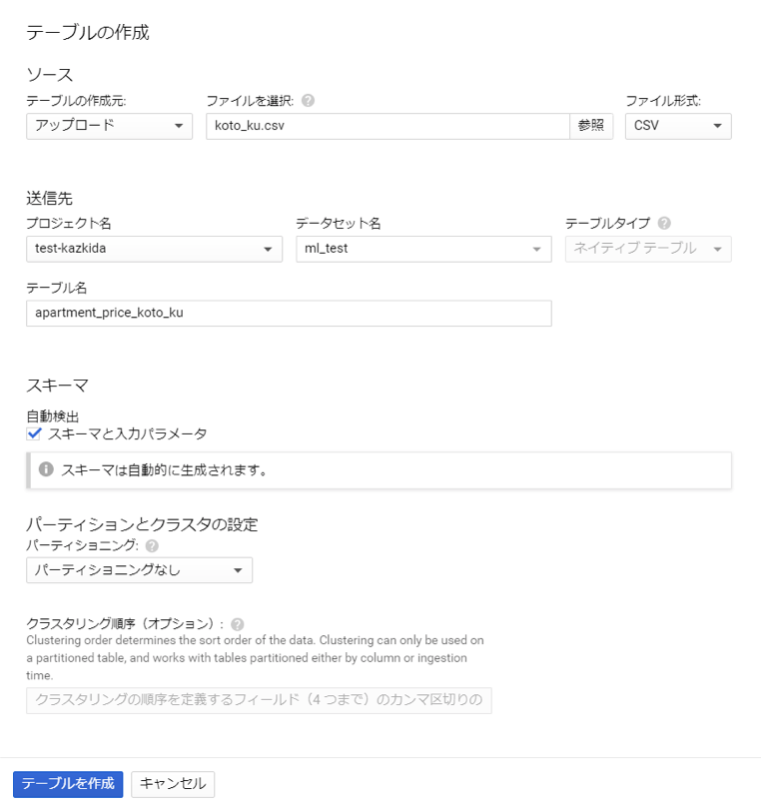
整形の完了したcsvファイルをBigQueryにアップロードします。
詳細手順は割愛しますが、以下の手順です。
- BigQueryのアカウントを開設する
- プロジェクトを作成する
- データセットを作成する
- ファイルをアップロードする(以下の画面コピーをご参照ください。)
3. モデルの作成
機械学習から出力する予測値には、大別して2種類あります。
- 離散変数が返ってくるもの(『ユーザーが「購入する」と「しない」』、とか、『アヤメの種類が「Setosa」か、「Versicolour」か「Virginica」のどれか』など)分類タスク、クラシフィケーションタスクとも呼ばれるタスク設定からの戻り値です。
- 連続変数が返ってくるもの(『「最終学歴」、「住所」、「勤務先の企業の業種」などから、「推定される年収」』を得たり、『「年収」、「ローンの残高」、「勤続年数」から、「推定される貸し倒れ確率」』を得たり。など)回帰タスク、リグレッションタスクなどと呼ばれるタスク設定からの戻り値です。
BigQueryのMLエンジンは、前者に対しては、ロジスティック回帰モデル(回帰と付いていますが、分類を行います。)を、後者については、線形回帰モデルを提供しています。
今回は、「推定取引額」という連続値を取り出したいので、線形回帰モデルを利用します。
以下がBigQueryの「クエリエディタ」に記述するモデル作成のためのSQL文の書式です。たった12行です。

各行の説明は以下です。
- 1行目:モデルを作成し、ml_testデータセット配下に、koto_jという名前で保存しなさい。という命令です。
- 2行目:線形回帰モデルを利用しなさい。という命令です。
- 3行目:表の中のpriceという列を推測したい値としますよ。という宣言です。
- 4行目:モデルにインプットする列を指定しています。
- 5行目~11行目:推測してほしいpriceや、各種の特徴量を指定しています。
- 12行目:5~11行目をどのテーブルから取ってきほしいのか?を指定しています。
どうでしょう?それほど難しくない・・・と感じた方も多いのではないでしょうか?
4. 「モデル」の評価
私の環境では、20秒程度でモデルが完成します。そこで、次にモデルの評価へと進みます。
モデルの評価もBigQueryのクエリエディタにSQL文を記述し、実行することで行います。記述するSQL文は以下の通りです。ml.evaluateという関数を利用します。

各行の説明は以下です。
1行目:先程作成したモデルを評価してください。という命令です。
2行目~10行目:モデルを作成したときの4行目~12行目と同じです。
上記のクエリを実行すると、一秒もたたないうちに以下の結果を得ることができます。

6種類の値が返ってきますが、重要なのは、以下の2つです。
mean_absolute_error(MAE) : 「誤差の絶対値」の平均です。上記ではモデルを評価した結果、平均して486万円くらい誤差が出ますよ。と教えてくれます。江東区の中古マンションの相場は数千万円程度と思われますので、500万円以下の誤差は、まぁ、許容範囲かもしれません。(ただ、あくまでも平均なので、どのような条件でもその程度の誤差に収まることを保証しているものではないことに注意が必要です。)
r2_square(R-2乗値):線形回帰モデルが評価したデータにどの程度当てはまっているか?の度合いです。0.7というのは中の上程度の当てはまりを示しています。ギリギリ現実世界でも利用できる値かと思います。
5. 特徴量の調整やモデルのオプションの調整
500万円程度のMAE、0.7程度のR-2乗値に満足できない場合、特徴量の調整やモデルのオプションの調整を行うことになります。
また、あまりにも当てはまりが悪いと、BigQueryは、以下のメッセージを返してくれることがあります。


以下が「意訳」です。

このメッセージをすべて理解できている訳ではありませんが、「過学習」とは、作成したモデルが訓練データに対してはよく当てはまるが検証データには当てはまりが悪い。という状態です。持っている情報の量に比べて、過度に複雑なモデルを作ってしまうことで発生します。
正則化とは、特徴量のうちのいくつかをあえて過小評価する、もしくは利用しないようにすることで、過学習を回避する一つの手法とでも理解すると良いと思います。
そこで、何回かの試行錯誤をした結果、最終的にモデルの評価を以下まで改善することができました。

MAEは大して下げられませんでしたが、R-2乗値は0.76とある程度改善することができました。
6. 予測値の取り出し
R-2乗値0.76と、まあまあ満足できるモデルが完成しましたので、予測値を取り出してみます。ここでTableau Desktopを利用し、シミュレーションの効率を上げます。
例えば、以下の条件の中古マンションの、今回の機械学習モデルにおける論理的な予測値はいくらでしょう?
「築30年より前、35年以内」
「最寄り駅は南砂町」
「南砂町から徒歩13分」
「改装済」
「65平米」
SQL文を書くのはちょっと面倒です。そこでTableau Desktopの「パラメータ」機能を利用します。
BigQueryのモデルに接続するときに、パラメータでセットした値を投げる必要があるので、BigQueryに接続する際の、カスタムSQLは以下の通りになります。
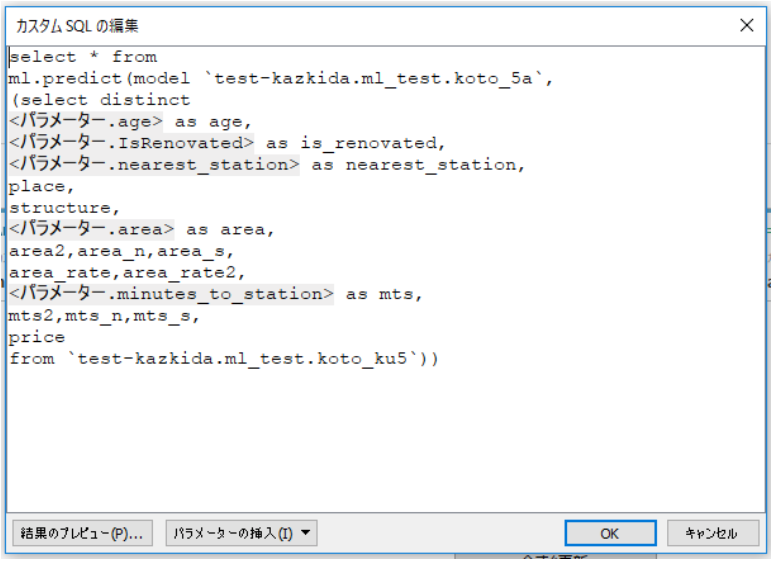
Viz上、パラメータで指定したい値にはパラメータを利用し、パラメータで指定しない値については、直接記述しています。
以下が補足です。
- ml.predictという関数が、予測を行う関数です。
- 特徴量エンジニアリング済のモデルを、koto_5aとして定義しています。
- 特徴量を2乗したり、正規化(値を0から1の間に分布するように実際の値(面積や、駅からの徒歩分数)を割り当て直す)したり、標準化(平均が0、分散が1の分布となるように実際の値(面積や、駅からの徒歩分数)値を割り当て直す)した値も特徴量に加えています。(※)
※正規化や標準化にもTableau Desktopを利用しています。驚くほど簡単に実現でき、特徴量を増やすことができます。
データ接続に成功したら、Viz側でパラメータを調整します。
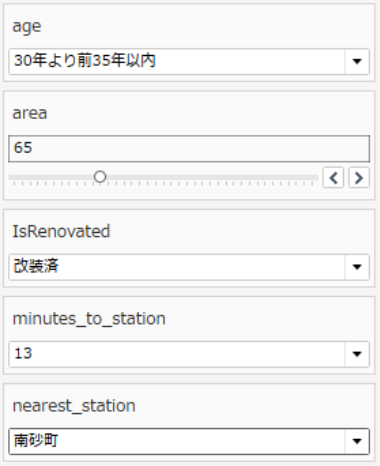
先程の条件を体現したパラメータ設定は以下となります。パラメータを変更するたびに、データセットに対して、値を投げているのが分かります。1秒程度で結果が返ってきて、「平均(predicted_price)」が変化するのが分かります。
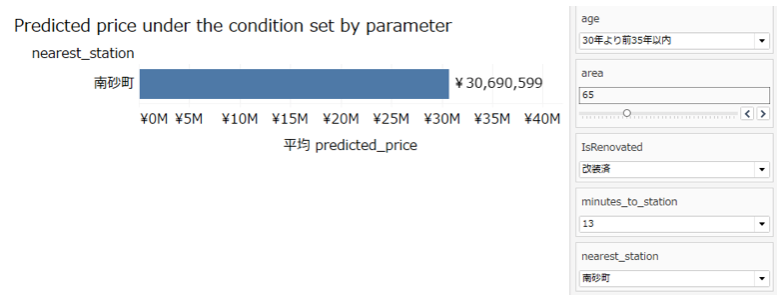
つまり、Bigquery MLで作成した、線形回帰モデル(R-2乗値0.76)に対して、リアルタイムでTableau Desktopのパラメータ経由でセットした値を投げて、ml.predict関数が計算した戻り値(予測値)である、predicted_priceの値をVizで表示している。ということです。
結果は、以下の通り、3,069万円でした。
7. 検算
では、検算してみましょう。上記条件の中古マンションはいくらで販売されているのでしょうか?
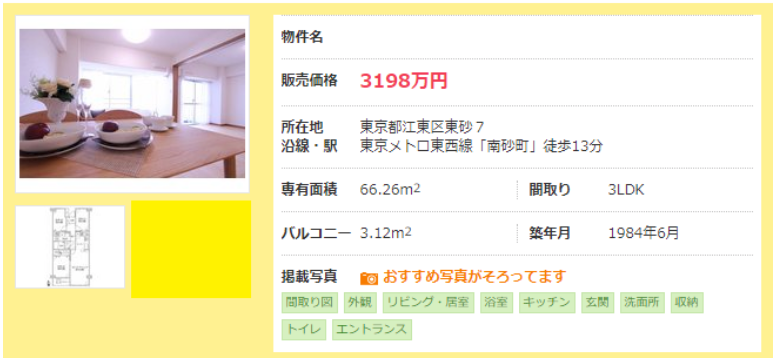
3,198万円・・・。予測値との誤差は4.2%(129万円)。機械学習もなかなかの精度です。
一方、どんな条件でも、これほどの正確さがでるのかというとそうではなく、
実売価格2億9800万円の豊洲のマンションに対して、論理上の予想金額が5400万円。という著しく異なる値を返したりもしています。
データの少ない価格帯では推測の精度が下がる。。。ということかもしれません。
まとめ
ここまで読み進めていただいてありがとうございました。BigQuery MLを利用した中古マンション価格推測の実際の手順を紹介する本ブログ記事は如何でしたでしょうか?
詳細はともかく、全体像をご理解いただければ大変ありがたいです。
以下がまとめです。
- BigQueryに機械学習させるデータの整形にはTableau Prepが便利
- BigQuery MLは、「モデルをcreateする(ml.create句を利用)」、「作成したモデルをevaluateする(ml.evaluate句を利用)」、「作成したモデルに従ってpredictする(ml.predict句を利用)」の3段階であり、それ自体は難しくない。
- 精度を高めるための特徴量エンジニアリングや、モデル作成時のオプションの調整はちょっと難しい。(が、何をしているか完全に理解しなくても、精度を上げるような調整ができれば良い。という割り切りも必要。)
- 特徴量を増やすにはTableau Desktopの計算フィールドを利用するのが非常に便利
- R-2乗値が0.76程度あれば、(データがたくさんある価格帯であれば)比較的精度高く予測できた。
- Tableau Desktopのパラメータを使うと、シミュレーションは非常に簡単になる。
次はマーケティングデータでBigQueryの機械学習モデルを利用してみたいと思います。
Special Thanks
This blog post is the child of the inspiration given by Nathan, who kindly lectured me about the topic as long as 2 hours among other topics. He showed the “original” blog post of his colleague Pierce Young.

The “original” blog post is here.
Special thanks to Nathan, KT and Yamazaki-san.







